Multi-platform programming
Software Process Engineering
Giovanni Ciatto — giovanni.ciatto@unibo.it
Compiled on: 2026-07-25 — printable version
Multi-platform programming
Preliminaries
What are software platforms?
-
Fuzzy concept
- often mentioned in courses / literature, yet not precisely defined
-
Insight:
The substratum upon which software applications run
What are software platforms?
Operative systems (?)
What are software platforms?
Operative systems + ???
-
Programming languages?
- not that simple
- e.g. Scala apps can call Java code
- not that simple
-
Runtimes
- i.e. the set of libraries and conventions backing programming languages
What are software platforms?
Definition attempt
Software platform $\stackrel{\Delta}{=}$ anything having an API enabling the writing of applications, and the runtime supporting the execution of those applications
- thank you chap, what are API and runtimes then?
What are API and runtimes?
API $\equiv$ application programming interface(s) $\stackrel{\Delta}{=}$ a formal specification of the set of functionalities provided by a software (sub-)system for external usage, there including their input, outputs, and environmental preconditions and effects
- client-server metaphor is implicit
Runtime [system/environment] $\approx$ the set of computational resources backing the execution of a software (sub-)system
- we say that “runtimes support API”
What are API and runtimes?
Examples of API
-
all possible public interfaces / classes / structures in an OOP module
- and their public/protected methods / fields / properties / constructors
- and their formal arguments, return types, throwable exceptions
- and their public/protected methods / fields / properties / constructors
-
all possible commands a CLI application accept as input
- and their admissible sub-commands, options, and arguments
- and the corresponding outputs, exit values, and side effects
- and their admissible sub-commands, options, and arguments
-
all possible routes a Web service may accept HTTP request onto
- and their admissible HTTP methods
- and their admissible query / path / body / header parameters
- and the corresponding status codes, and response bodies
- and their admissible query / path / body / header parameters
- and their admissible HTTP methods
What are API and runtimes?
Examples of runtimes
-
any interpreter (JVM, CRL, CPython, V8)
- and their standard libraries
- and their type system and internal conventions
- eg value/reference types in JVM/CRL, global lock in CPython
-
any operative system (Win, Mac, Linux)
- and their system calls, daemons, package managers, default commands, etc
- and their program memory, access control, file system models
-
any Web service
- and the protocols they leverage upon
- and their URL structuring model
- the data schema of their input/output objects
- the authentication / authorization mechanisms they support
Notable platforms
-
The Java Virtual Machine (JVM)
- supported languages: Java, Kotlin, Scala, Clojure, etc.
-
.NET’s [pronounced “dot NET”] Common Language Runtime (CRL)
- supported languages: C#, VB.NET, F#, etc.
-
Python 3
- supported language: Python
-
NodeJS (V8)
- supported language: JavaScript, TypeScript, etc.
-
Each browser may be considered as a platform per se
- supported language: JavaScript
-
…
Practical features of platforms
-
standard libraries
- i.e. pre-cooked functionalities developers / users may exploit
-
predefined design decisions
- e.g. global lock in Python, event loop in JavaScript, etc.
-
organizational, stylistic, technical conventions
- e.g. project structure, code linting, nomenclature, etc.
-
packaging conventions, import mechanisms, and software repositories
- e.g. classpath for the JVM, NPM for JS, Pip + Pypi for Python, etc.
-
user communities
- e.g. many Data scientists use Python, many Web developers use JVM / JS
Example: the JVM platform
Standard libraries
-
Types from the
java.*andjavax.*packages are usable from any JVM language -
Many nice functionalities covering:
- multi-threading, non-blocking IO, asynchronous programming
- OS-independent GUI, or IO management
- data structures and algorithms for collections and streams
- unlimited precision arithmetic
-
Many functionalities are provided by community-driven third party libraries
- e.g. YAML/JSON parsing / generation, CSV parsing, complex numbers
Predefined design decisions
-
Everything is (indirectly) a subclass/instance of
Object- except fixed set of primitive types, and static stuff
-
Every object is potentially a lock
- useful for concurrency
-
Default methods inherited by
Objectclass- e.g.
toString,equals,hashCode
- e.g.
-
All methods are virtual by default
-
…
Organizational, stylistic, technical conventions
-
Project should be organized according to the Maven’s standard directory layout
-
Official stylistic conventions for most JVM languages
- e.g. type names in
PascalCase, members names incamelCase - e.g. getters/setters in Java vs. Kotlin’s or Scala’s properties
- e.g. type names in
-
Many technical conventions:
- iterable data structures should implement the
Iterableinterface - variadic arguments are considered arrays
- constructors for collections subclasses accept
Iterables as input - …
Packaging conventions, import mechanisms, and software repositories
-
Project files are organized into packages
- packages must correspond to directory structures
-
Code archives (
.jar) are Zip files containing compiled classes -
Basic import mechanism: the class path
- i.e. the path where classes are looked for
- commonly set at application startup
-
Many third-party repositories for JVM libraries
- Maven central repository is the most relevant one
- many tools for dependency management (e.g. Maven, Gradle)
User communities
-
Android developers
-
Back-end Web developers
-
Desktop applications developers
-
Researchers in the fields of: semantic Web, multi-agent systems, etc.
-
…
Example: the Python platform
Standard libraries
-
Notably, one the richest standard libraries ever
-
Many nice functionalities covering:
- all the stuff covered by Java
- plus many more, e.g. complex numbers, JSON and CSV parsing, etc
-
Many functionalities are provided by community-driven third party libraries
- e.g. scientific or ML libraries
Predefined design decisions
-
Everything is (indirectly) a subclass/instance of
object- no exceptions
-
Global Interpreter Lock (GIL)
-
Magic methods supporting various language features
- e.g.
__str__,__eq__,__iter__
- e.g.
-
No support for overloading
-
Variadic and keywords arguments
-
…
Organizational, stylistic, technical conventions
-
Project files should be organized according to Kenneth Reitz’s layout
-
Official stylistic conventions for Python (PEP8)
- e.g. type names in
PascalCase, members names insnake_case - e.g. indentation-aware syntax, blank line conventions, etc.
- …
- e.g. type names in
-
Many technical conventions:
- duck typing
- iterable data structures should implement the
__iter__method - variadic arguments are considered tuples
- keyword arguments are considered sets
- …
Packaging conventions, import mechanisms, and software repositories
-
Project files are organized into packages and modules
- packages $\leftrightarrow$ directories
- modules $\leftrightarrow$ files
-
Code archives (
.whl) are Zip files containing Python sources -
Each Python environment has an internal folder where installed libraries are stored
pipsimply unzips modules/packages in thereimportstatements look for packages/modules in there
-
Pypi as the official repository for Python libraries
pipas the official tool for dependency management
User communities
-
Data-science community
-
Back-end Web developers
-
Desktop applications developers
-
System administrators
-
…
Example: the NodeJS platform
Standard library
-
Very limited standard library from JavaScript
- enriched with many Node modules
-
Many nice functionalities covering:
- networking and IPC
- OS, multiprocess, and cryptographic utilities
-
Many functionalities are provided by community-driven third party libraries
- you can find virtually anything on npmjs.com
Predefined design decisions
-
Object orientation based on prototypes
-
Single threaded design + event loop
-
Asynchronous programming via continuation-passing style
Organizational, stylistic, technical conventions
-
Project structure is somewhat arbitrary (no established convention)
- the project must contain a
package.jsonfile in the root directory - declaring the entry point of the project
- the project must contain a
-
Many structure conventions co-exist
- e.g. W3School’s one
-
Many technical conventions:
- duck typing
- magic variables, e.g. for prototype
- …
Packaging conventions, import mechanisms, and software repositories
-
Project files are organized into modules
- modules are file containing anything
- and declaring what to export
-
Code archives (
.tar.?z) are compressed tarball files containing JS sources -
Third-party libraries can be installed via
npm- locally, for the user, or globally
-
NPM as the official repository for JS libraries
npmas the official tool for dependency management
User communities
-
Front-end Web developers
-
Back-end Web developers
-
GUI developers
-
…
Platforms from software developers’ perspective
The choice of a platform impacts developers during:
-
the design phase
-
the implementation phase
-
the testing phase
-
the release phase
How platform affects the design phase
- One may choose the platform which minimizes the abstraction gap w.r.t. the problem at hand
Abstraction gap $\approx$ the space among the problem and the prior functionalities offered by a platform. Ideally, the bigger the space the more effort is required to build the solution

How platform affects the implementation phase
-
Developers write solutions by leveraging the API of the platform
-
… as well as the API of any third-party library available for that platform

How platform affects the testing phase
-
Test suites are a “project in the project”
- so remarks are similar w.r.t. the implementation phase
-
One may test the system against as many versions as possible of the underlying platforms
-
One may test the system against as many OS as possible
- virtual platforms may behave differently depending on the OS
How platform affects the release phase
Release $\approx$ publishing some packaged software system onto a repository, hence enabling its import and exploitation
-
Packaging systems are platform-specific…
-
Repositories are platform-specific…
-
… release is therefore platform specific
Platform choice for a new SW project
-
Choice is commonly driven by design / technical decisions
- which platform would ease developers’ work the most?
-
However, choosing the platform is a business decision as well
- platforms have user communities
- SW project benefit from wide(r) user communities
-
Business decision: which user communities to target?
- what are the most relevant platforms for that communities?
-
Coherency is key for success in platform selection
- coherently choose the target community w.r.t SW goal
- coherently choose the platform w.r.t. target community
General benefits of coherence
-
The abstraction gap is likely lower
-
More third party libraries are likely available
-
The potential audience is wider
- implies the SW project is more valuable
-
Easier to find support / help in case of issues
-
More likely that third-party issues are timely fixed
What about research-oriented software? (pt. 1)
Researchers may act as software developers
-
to elaborate data
-
to create in-silico experiments
-
to study software system
-
to create software tools improving their research
-
to create software tools for the community
- this is how many FOSS tools have been created
What about research-oriented software? (pt. 2)
Research institutions are not software houses
-
Personnel can only dedicate a fraction of their time to development
-
Most software artifacts are disposable (1, 2, 4)
-
Development efforts are discontinuous
-
Development teams are small
-
Software is commonly a means, not an objective
-
Commitment to software development is:
- commonly on the individual
- sometimes on the project
- rarely on the institution
What about research-oriented software? (pt. 3)
Research-oriented software development should maximise audience and impact, while minimising development and maintenance effort
-
Science requires reproducibility
- wide(r) user base is a facilitator for reproducility
-
The wider the community, the wider the impact of community-driven research software
- more potential citations
-
Minimising effort can be done by improving efficiency
- by means of software engineering
General benefits of coherence, for researchers
Choosing the right community / platform is strategical for research-oriented software
-
The abstraction gap is likely lower
- less development effort
-
More third party libraries are likely available
- less development effort
-
The potential audience is wider
- more value, more impact, more reproducibility
-
Easier to find support / help in case of issues
- potentially, less development effort
-
More likely that third-party issues are timely fixed
- potentially, less development effort
About technological silos
Silos (in IT) are software components / systems / ecosystems having poor external interoperability (i.e. software from silos A hardly interoperates with software from silos B)
-
Platforms are (pretty wide) software silos
- making software from any two platforms interoperate is non-trivial
- making software from the same platform interoperate is easier
-
Examples:
- intra-platform: Kotlin program calling Java library
- inter-platform: Python program calling native library
Open research communities vs. technological silos
-
Research communities in CS / AI may overlap with platforms communities:
- e.g. neural networks researchers $\rightarrow$ Python
- e.g. data science $\rightarrow$ Python | R
- e.g. symbolic AI $\rightarrow$ JVM | Prolog
- e.g. multi-agent systems $\rightarrow$ JVM
- e.g. semantic-web $\rightarrow$ JVM | Python
-
What about inter-community research efforts?
- they may need interoperability among different silos
- in lack of which, research is slowed down
Multi-platform programming is an enabler for inter-community research
The need for multi-platform programming
- Ideal goal:
let the same software tool run on multiple platforms
- More reasonable goal:
Create multiple artifacts, one per each supported platform, sharing the same design and functioning
- Practical goal:
design and write the software once, then port it to several platforms
Approaches for multi-platform programming
-
Write once, build anywhere
- software is developed using some sort of “super-language”
- code from the “super-language” is automatically compiled for all platforms
-
Write first, wrap elsewhere
- software is developed for some principal platform
- implementations for all other platforms are wrappers of the first one
Write once, build anywhere (concept)

Write once, build anywhere (explanation)
-
Assumptions:
- one “super-language” exists, having:
- a code-generator targeting multiple platforms
- e.g. compiler, transpiler, etc.
- the same standard library implemented for all those platforms
- a code-generator targeting multiple platforms
- one “super-language” exists, having:
-
Workflow:
-
Design, implement, and test most of the project via the super-language
- this is the platform-agnostic (a.k.a. “common”) part of the project
-
Complete, refine, or optimise platform-specific aspects via
- platform-specific code
- platform-specific third-party libraries
-
Build platform-specific artifacts, following platform-specific rules
-
Upload platform-specific artifacts on platform-specific repositories
-
Write once, build anywhere (analysis)
Let N be the amount of supported platforms
-
Platform-agnostic functionalities require effort which is independent from
N -
Platform-specific functionalities require effort proportional to
N -
Better to minimise platform-specific code
- by maximising common code
- this is true both for main code and for test code
-
Relevant questions:
- what to realise as common code? what as platform-specific code?
- how to set the boundary of the common (resp. platform-specific) code?
Takeaway
The abstraction gap of the common code is as wide as the one of the platform having the widest abstraction gap

Write once, build anywhere (strategy)
Whenever a new functionality needs to be developed:
-
Try to realise it with common std-lib only
-
If not possible, try to maximise the portion of platform-agnostic code
- make it possible to plug platform-specific aspects
- For each functionality which cannot be realised as purely platform-agnostic:
- design a platform-agnostic interface
- implement the interface
Ntimes, one per target platform
Write first, wrap elsewhere (concept)

Write first, wrap elsewhere (explanation)
-
Assumptions:
- one “main” platform exists such that
- code from the “main” platform can be called from other target platforms
- the software has been designed in a platform-agnostic way
- one “main” platform exists such that
-
Workflow:
-
Fully implement, test, and deploy the software for the main platform
-
For all other platforms:
-
re-design and re-write platform-specific API code
-
implement platform-specific API by calling the main platform’s code
-
re-write test for API code
-
build platform-specific packages, wrapping the main platform’s package and runtime
-
Upload platform-specific artifacts on platform-specific repositories
-
Write first, wrap elsewhere (analysis)
Let N be the amount of supported platforms
-
Clear separation of API code from implementation code is quintessential
-
The effort required for writing API code is virtually the same on all platforms
-
Global effort is sub-linearly dependent on
N- implementing API and wrapper code is a manual task
- still less effort than implementing the same design
Ntimes
-
The
i-th platform’s wrapper code will only call the main platform’s API code -
Relevant questions:
- how to deal with platform-specific aspects?
- how to create platform-agnostic design?
Multi-platform programming
Write once, build anywhere
Write once, build anywhere with Kotlin
-
JetBrains-made modern programming language
- focused on “practical use” (whatever that means)
-
Gaining momentum since Google adopted is as official Android language
- along with Java and C++
-
Clearly inspired by a mixture of Java, C#, Scala, and Groovy
- standard library clearly inspired to Java’s one
-
Born in industry, for the industry
- initially considered a better java
- focused on getting productive quickly and reducing programming errors
-
Acts as the “super language” supporting the “write once, build anywhere” approach
- Kotlin compilers are available for several platforms
- standard library implemented for those platforms
Kotlin: supported platforms (a.k.a. targets)
Reference: https://kotlinlang.org/docs/reference/mpp-dsl-reference.html
-
JVM
- first and best supported platform
- may target a specific JDK version: prefer
11
-
JavaScript (JS)
- requires choosing among Browser support, Node support or both
- the two sub-targets have different runtimes
-
Native
- supporting native may imply dealing with 3+ targets
- cross-compilation is not yet supported
Kotlin: supported platforms, Native sub-targets
Reference: https://kotlinlang.org/docs/reference/mpp-dsl-reference.html
-
Win by MinGW, Linux
- must pay attention to architecture
- MinGW is not exactly “vanilla” Windows environment
-
iOS, macOS
- requires Apple facilities (e.g. XCode)
- may imply further costs
-
Android
- requires Android SDK
Gradle as the tool for build automation
-
Building a multi-platform Kotlin project is only supported via Gradle
- no real alternatives here
-
Gradle is a build automation + dependency management system
-
Gradle simultaneously enables & constrains the multi-platform workflow
- pre-defined project structure
- pre-defined development workflow
- enforced code partitioning
- ad-hoc tasks for platform specific/agnostic compilation, testing, deploy, etc.
Kotlin multi-platform project structure
Common
Kotlin enforces strong segregation of the platform-agnostic and platform-specific parts
-
common main code: platform-agnostic code which only depends on:
- the Kotlin std-lib
- plus other third-party Kotlin multi-platform libraries
-
common test code: platform-agnostic test code which only depends on:
- the common main code and all its dependencies
- some Kotlin multi-platform testing library (e.g.
kotlin.testor Kotest)
Kotlin multi-platform project structure
Platform-specific
- for each target platform
T(e.g.jvm,js, etc.)-
T-specific main code: main Kotlin code targeting theTplatform, depending on:- the common main code and all its dependencies
T-specific standard libraryT-specific third-party libraries
-
T-specific test code: test Kotlin code targeting theTplatform, depending on:T-specific main codeT-specific test libraries
-
Kotlin multi-platform project structure (example)
<root>/
│
├── build.gradle.kts # multi-platform build description
├── settings.gradle.kts # root project settings
│
└── src/
├── commonMain/
│ └── kotlin/ # platform-agnostic Kotlin code here font-weight: normal;
├── commonTest/
│ └── kotlin/ # platform-agnostic test code written in Kotlin here
│
├── jvmMain/
│ ├── java/ # JVM-specific Java code here
│ ├── kotlin/ # JVM-specific Kotlin code here
│ └── resources/ # JVM-specific resources here
├── jvmTest
│ ├── java/ # JVM-specific test code written in Java here
│ ├── kotlin/ # JVM-specific test code written in Kotlin here
│ └── resources/ # JVM-specific test resources here
│
├── jsMain/
│ └── kotlin/ # JS-specific Kotlin code here
├── jsTest/
│ └── kotlin/ # JS-specific Kotlin code here
│
├── <TARGET>Main/
│ └── kotlin/ # <TARGET>-specific Kotlin code here
└── <TARGET>Test/
└── kotlin/ # <TARGET>-specific test code written in Kotlin here
Kotlin multi-platform build configuration (pt. 1)
Defines several aspects of the project:
-
which version of the Kotlin compiler to adopt
plugins { kotlin("multiplatform") version "1.9.10" // defines plugin and compiler version } -
which repositories should Gradle use when looking for dependencies
repositories { mavenCentral() // use MCR for downloading dependencies (recommended) // other custom repositories here (discouraged) }
Kotlin multi-platform build configuration (pt. 2)
Defines several aspects of the project:
-
which platforms to target (reference here)
kotlin { // declares JVM as target jvm { withJava() // jvm-specific targets may include java sources } // declares JavaScript as target js { useCommonJs() // use CommonJS for JS dependencies management // or useEsModules() binaries.executable() // enables tasks for Node packages generation // the target will consist of a Node project (with NodeJS's stdlib) nodejs { runTask { /* configure project running in Node here */ } testRuns { /* configure Node's testing frameworks */ } } // alternatively, or additionally to nodejs: browser { /* ... */ } } // other targets here } -
other admissible targets:
android- various native sub-targets (details here)
Kotlin multi-platform build configuration (pt. 3)
- which third-party library should each target depend upon
kotlin { sourceSets { val commonMain by getting { dependencies { api(kotlin("stdlib-common")) implementation("group.of", "multiplatform-library", "X.Y.Z") // or api } } val commonTest by getting { dependencies { implementation(kotlin("test-common")) } } val jvmMain by getting { dependencies { api(kotlin("stdlib-jdk8")) implementation("group.of", "jvm-library", "X.Y.Z") // or api } } val jvmTest by getting { dependencies { implementation(kotlin("test-junit")) } } val jsMain by getting { dependencies { api(kotlin("stdlib-js")) implementation(npm("npm-module", "X.Y.Z")) // lookup on https://www.npmjs.com } } val jsTest by getting { dependencies { implementation(kotlin("test-js")) } } } }
Kotlin multi-platform build configuration (pt. 4)
-
configure Kotlin compiler options
kotlin { sourceSets.all { languageSettings.apply { // provides source compatibility with the specified version of Kotlin. languageVersion = "1.8" // possible values: "1.4", "1.5", "1.6", "1.7", "1.8", "1.9" // allows using declarations only from the specified version of Kotlin bundled libraries. apiVersion = "1.8" // possible values: "1.3", "1.4", "1.5", "1.6", "1.7", "1.8", "1.9" // enables the specified language feature enableLanguageFeature("InlineClasses") // language feature name // allow using the specified opt-in optIn("kotlin.ExperimentalUnsignedTypes") // annotation FQ-name // enables/disable progressive mode progressiveMode = true // false by default } } } -
details about:
Build configuration: full example
plugins {
kotlin("multiplatform") version "1.9.10"
}
repositories {
mavenCentral()
}
kotlin {
jvm {
withJava()
}
js {
nodejs {
runTask { /* ... */ }
testRuns { /* ... */ }
}
// alternatively, or additionally to nodejs:
browser { /* ... */ }
}
sourceSets {
val commonMain by getting {
dependencies {
api(kotlin("stdlib-common"))
implementation("group.of", "multiplatform-library", "X.Y.Z") // or api
}
}
val commonTest by getting {
dependencies {
implementation(kotlin("test-common"))
}
}
val jvmMain by getting {
dependencies {
api(kotlin("stdlib-jdk8"))
implementation("group.of", "jvm-library", "X.Y.Z") // or api
}
}
val jvmTest by getting {
dependencies {
implementation(kotlin("test-junit"))
}
}
val jsMain by getting {
dependencies {
api(kotlin("stdlib-js"))
implementation(npm("npm-module", "X.Y.Z")) // lookup on https://www.npmjs.com
}
}
val jsTest by getting {
dependencies {
implementation(kotlin("test-js"))
}
}
all {
languageVersion = "1.8"
apiVersion = "1.8"
enableLanguageFeature("InlineClasses")
optIn("kotlin.ExperimentalUnsignedTypes")
progressiveMode = true // false by default
}
}
}
Gradle tasks for multi-platform projects (pt. 1)
Let T denote the target name (e.g. jvm, js, etc.)
-
<T>MainClassescompiles the main code for platformT- e.g.
jvmMainClasses,jsMainClasses
- e.g.
-
<T>TestClassescompiles the test code for platformT- e.g.
jvmTestClasses,jsTestClasses
- e.g.
-
<T>Jarcompiles the main code for platformTand produces a JAR out of it- e.g.
jvmJar,jsJar - depends on (hence implies)
<T>MainClasses, but NOT<T>TestClasses
- e.g.
-
<T>Testexecutes tests for platformT- e.g.
jvmTest,jsTest - depends on (hence implies)
<T>MainClasses, AND on<T>TestClasses
- e.g.
Gradle tasks for multi-platform projects (pt. 2)
-
compileProductionExecutableKotlinJscompiles the JS main code into a Node project- requires the
jstarget to be enabled - requires the
binaries.executable()configuration to be enabled
- requires the
-
assemblecreates all JARs (hence compiling for main code for all platforms)- it also generates documentation and sources JAR
- if publishing is configured
- it also generates documentation and sources JAR
-
testexecutes tests for all platforms -
checkliketestbut it may also include other checks (e.g. style) if configured -
build$\approx$check+assemble
Multi-platform Kotlin sources
-
Ordinary Kotlin sources
-
When in
common:- only the platform-agnostic std-lib can be used
- API reference here (recall to disable all targets except
Common)
- API reference here (recall to disable all targets except
- one may use third-party libraries, as long as they are multi-platform too
- one may use the
expectkeyword - one may use platform-specific annotations
- e.g.
@JvmStatic,@JsName, etc.
- e.g.
- only the platform-agnostic std-lib can be used
Multi-platform Kotlin sources
Let T denote some target platform
-
When in
T-specific source sets- one may use the
T-specific std-lib - one may use the
T-specific Kotlin libraries - one may use the
T-specific libraries - one may use the
actualkeyword
- one may use the
-
Each platform
Tmay allow for specific keywords- e.g. the
externalmodifier
- e.g. the
The expect/actual mechanism for specialising common API
-
Declaring an
expected function / type declaration in common code… -
… enforces the existence of a corresponding
actualdefinition for all platforms- compiler won’t succeed until an actual definition is provided for each target

Workflow (top-down)
-
Draw a platform-agnostic design for your domain entities
- keep in mind that you can only rely on a very small std-lib / runtime
- keep in mind that some API may be missing in the common std-lib:
- e.g. file system API
- try to reason in a platform-agnostic way
- e.g. file system makes no sense for in-browser JS
- separate interfaces from classes
- rely on abstract classes with template methods to maximise common code
- use
expectkeyword to declare platform-agnostic factories
-
Assess the abstraction gap, for each target platform
-
For each target platform:
- draw a platform-specific design extending the platform-agnostic one
- … and filling the abstraction gap for that target
- implement interfaces via platform-specific classes
- implement platform-specific concrete classes for common abstract classes
- use
actualkeyword to implement platform-specific factories
Running example
Multi-platform CSV parsing lib
-
CSV (comma-separated values) files, e.g.:
# HEADER_1, HEADER_2, HEADER_3, ... # character '#' denotes the beginning of a single-line comment # first line conventionally denotes columns names (headers) field1, filed2, field3, ... # character ',' acts as field separator "field with spaces", "another field, with comma", "yet another field", ... # character '"' acts as field delimiter # other characters may be used to denote comments, separators, or delimiters -
JVM and JS std-lib do not provide direct support for CSV
-
Requirements:
- library for parsing / manipulating CSV files
- parsing = loading from file
- manipulating = creating / editing / saving CSV files, programmatically
- support for both JVM and JS
About the example
-
We’ll follow a domain-driven approach:
- focus on designing / implementing the domain entities
- then, we’ll add functionalities for manipulating them
- finally, we’ll write unit and integration tests
-
Domain entities (can be realised as common code):
Table: in-memory representation of a CSV fileRow: generic row in a CSV fileHeader: special row containing the names of the columnsRecord: special row containing the values of a line in a CSV file
-
Main functionalities (require platform specific code):
- creating a
Tableprogrammatically - reading columns, rows, and values from a
Table - parsing a CSV file into a
Table - saving a
Tableinto a CSV file
- creating a
Domain entities
top to bottom direction
package “kotlin” {
interface Iterable
package “io github gciatto csv” {
interface Row {
+ get(index: Int): String
+ size: Int
}
Row -up-|> Iterable: //T// = String
interface Header {
+ columns: List<String>
+ contains(column: String): Boolean
+ indexOf(column: String): Int
}
Row <|-- Header
interface Record {
+ header: Header
+ values: List<String>
+ contains(value: String): Boolean
+ get(column: String): String
}
Row <|-- Record
Record "1" *-right- "*" Header
interface Table {
+ header: Header
+ records: List<Record>
+ get(row: Int): Row
+ size: Int
}
Table "1" *-u- "*" Header
Table "*" o-u- "*" Record
Table -u----|> Iterable: //T// = Row
}
The Row interface
// Represents a single row in a CSV file.
interface Row : Iterable<String> {
// Gets the value of the field at the given index.
operator fun get(index: Int): String
// Gets the number of fields in this row.
val size: Int
}
The Header interface
// Represents the header of a CSV file.
// A header is a special row containing the names of the columns.
interface Header : Row {
// Gets the names of the columns.
val columns: List<String>
// Checks whether the given column name is present in this header.
operator fun contains(column: String): Boolean
// Gets the index of the given column name.
fun indexOf(column: String): Int
}
The Record interface
// Represents a record in a CSV file.
interface Record : Row {
// Gets the header of this record (useful to know column names).
val header: Header
// Gets the values of the fields in this record.
val values: List<String>
// Checks whether the given value is present in this record.
operator fun contains(value: String): Boolean
// Gets the value of the field in the given column.
operator fun get(column: String): String
}
The Table interface
// Represents a table (i.e. an in-memory representation of a CSV file).
interface Table : Iterable<Row> {
// Gets the header of this table (useful to know column names).
val header: Header
// Gets the records in this table.
val records: List<Record>
// Gets the row at the given index.
operator fun get(row: Int): Row
// Gets the number of rows in this table.
val size: Int
}
Common implementations of domain entities
top to bottom direction
package “io github gciatto csv impl” { interface Row
abstract class AbstractRow { - values: List<String> # constructor(values: List<String>) # toString(type: String?): String }Row <|-d- AbstractRow
interface Header
class DefaultHeader { - indexesByName: Map<String, Int> + constructor(columns: Iterable<String>) }
Row <|-d- Header Header <|-d- DefaultHeader AbstractRow <|-d- DefaultHeader
interface Record
class DefaultRecord { + constructor(header: Header, values: Iterable<String>) }
Row <|-d- Record Record <|– DefaultRecord AbstractRow <|-d- DefaultRecord
class DefaultTable { + constructor(header: Header, records: Iterable<Record>) }
interface Table
Table <|– DefaultTable
}
The AbstractRow class
// Base implementation for the Row interface.
internal abstract class AbstractRow(protected open val values: List<String>) : Row {
override val size: Int
get() = values.size
override fun get(index: Int): String = values[index]
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (other == null || this::class != other::class) return false
return values == (other as AbstractRow).values
}
override fun hashCode(): Int = values.hashCode()
// Returns a string representation of this row as "<type>(field1, field2, ...)".
protected fun toString(type: String?): String {
var prefix = ""
var suffix = ""
if (type != null) {
prefix = "$type("
suffix = ")"
}
return values.joinToString(", ", prefix, suffix) { "\"$it\"" }
}
// Returns a string representation of this row as "Row(field1, field2, ...)".
override fun toString(): String = toString("Row")
// Makes it possible to iterate over the fields of this row, via for-each loops.
override fun iterator(): Iterator<String> = values.iterator()
}
The DefaultHeader class
// Default implementation for the Header interface.
internal class DefaultHeader(columns: Iterable<String>) : Header, AbstractRow(columns.toList()) {
// Cache of column indexes, for faster lookup.
private val indexesByName = columns.mapIndexed { index, name -> name to index }.toMap()
override val columns: List<String>
get() = values
override fun contains(column: String): Boolean = column in indexesByName.keys
override fun indexOf(column: String): Int = indexesByName[column] ?: -1
override fun iterator(): Iterator<String> = values.iterator()
override fun toString(): String = toString("Header")
}
The DefaultRecord class
internal class DefaultRecord(override val header: Header, values: Iterable<String>) : Record, AbstractRow(values.toList()) {
init {
require(header.size == super.values.size) {
"Inconsistent amount of values (${super.values.size}) w.r.t. to header size (${header.size})"
}
}
override fun contains(value: String): Boolean = values.contains(value)
override val values: List<String>
get() = super.values
override fun get(column: String): String =
header.indexOf(column).takeIf { it in 0 ..< size }?.let { values[it] }
?: throw NoSuchElementException("No such column: $column")
override fun toString(): String = toString("Record")
}
The DefaultTable class
internal class DefaultTable(override val header: Header, records: Iterable<Record>) : Table {
// Lazy, defensive copy of the records.
override val records: List<Record> by lazy { records.toList() }
override fun get(row: Int): Row = if (row == 0) header else records[row - 1]
override val size: Int
get() = records.size + 1
override fun iterator(): Iterator<Row> = (sequenceOf(header) + records.asSequence()).iterator()
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (other == null || other !is DefaultTable) return false
if (header != other.header) return false
if (records != other.records) return false
return true
}
override fun hashCode(): Int {
var result = header.hashCode()
result = 31 * result + records.hashCode()
return result
}
override fun toString(): String = this.joinToString(", ", "Table(", ")")
}
Need for factory methods
-
To enforce separation among API and implementation code, it’s better:
- to keep interfaces public, and classes internal
- to provide factory methods for creating instances of the interfaces
-
Convention in Kotlin is to create factory methods as package-level
functions- e.g. contained into the
io/github/gciatto/csv/Csv.ktfile
- e.g. contained into the
-
Factory methods may be named after the concept they create:
<concept>Of(args...)- e.g.
headerOf(columns...),recordOf(header, values...), etc.
- e.g.
-
Class diagram:
@startuml
skinparam monochrome false
class Csv{
+ headerOf(columns): Header
+ anonymousHeader(size: Int): Header
..
+ recordOf(header, values): Record
..
+ tableOf(header, records): Table
+ tableOf(rows): Table
}
@enduml
The Csv.kt file
// Headers creation from columns names
fun headerOf(columns: Iterable<String>): Header = DefaultHeader(columns)
fun headerOf(vararg columns: String): Header = headerOf(columns.asIterable())
// Creates anonymous headers, with columns named after their index
fun anonymousHeader(size: Int): Header = headerOf((0 ..< size).map { it.toString() })
// Records creation from header and values
fun recordOf(header: Header, columns: Iterable<String>): Record = DefaultRecord(header, columns)
fun recordOf(header: Header, vararg columns: String): Record = recordOf(header, columns.asIterable())
// Tables creation from header and records
fun tableOf(header: Header, records: Iterable<Record>): Table = DefaultTable(header, records)
fun tableOf(header: Header, vararg records: Record): Table = tableOf(header, records.asIterable())
// Tables creation from rows (anonymous header if none is provided)
fun tableOf(rows: Iterable<Row>): Table {
val records = mutableListOf<Record>()
var header: Header? = null
for (row in rows) {
when (row) {
is Header -> header = row
is Record -> records.add(row)
}
}
require(header != null || records.isNotEmpty())
return tableOf(header ?: anonymousHeader(records[0].size), records)
}
- Notice that each factory method is overloaded
- to support both
Iterableandvarargarguments - this is convenient for Kotlin programmers that will use our library
- to support both
Time for unit testing
-
Dummy instances object:
object Tables { val irisShortHeader = headerOf("sepal_length", "sepal_width", "petal_length", "petal_width", "class") val irisLongHeader = headerOf("sepal length in cm", "sepal width, in cm", "petal length", "petal width", "class") fun iris(header: Header): Table = tableOf( header, recordOf(header, "5.1", "3.5", "1.4", "0.2", "Iris-setosa"), recordOf(header, "4.9", "3.0", "1.4", "0.2", "Iris-setosa"), recordOf(header, "4.7", "3.2", "1.3", "0.2", "Iris-setosa") ) } -
Some basic tests in file
TestCSV.kt, e.g. (bad way of writing test methods, don’t do this at home)@Test fun recordBasics() { val record = Tables.iris(Tables.irisShortHeader).records[0] assertEquals("5.1", record[0]) assertEquals("5.1", record["sepal_length"]) assertEquals("0.2", record[3]) assertEquals("0.2", record["petal_width"]) assertEquals("Iris-setosa", record[4]) assertEquals("Iris-setosa", record["class"]) assertFailsWith<IndexOutOfBoundsException> { record[5] } assertFailsWith<NoSuchElementException> { record["missing"] } } -
Run tests via Gradle task
test(also try to run tests for specific platforms, e.g.jvmTestorjsTest)
Summary of what we did so far
-
We designed a set of domain entities
Row,Header,Record,Table- we provided a set of factory methods for creating instances of those entities
-
We implemented the domain entities as common code
-
We wrote some unit tests for the domain entities
- again as common code
-
Let’s focus now on more complex functionalities
- e.g. parsing a CSV file into a
Table - e.g. saving a
Tableinto a CSV file - all such features require I/O functionalities
- e.g. parsing a CSV file into a
I/O is platform-specific, hence we need platform-specific code
How much platform-specific code is needed?
-
I/O functionalities are supported by fairly different API in JVM and JS
- e.g. JVM’s
java.iopackage vs. JS’fsmodule - sadly, Kotlin std-lib does not provide a common API for I/O
- e.g. JVM’s
-
Do we need to rewrite the same business logic twice? (once for JVM, once for JS)
- yes, but we can minimise the amount of code to be rewritten
-
Let’s try to decompose the problem as follows:
- parsing CSV into
Table: file $\rightarrow$ string(s) $\rightarrow$Table - saving
Tableas CSV file:Table$\rightarrow$ string(s) $\rightarrow$ file
- parsing CSV into
-
Remarks:
- only the “file $\leftrightarrow$ string(s)” part is platform-specific
- conversely, the “string(s) $\leftrightarrow$
Table” part is platform-agnostic- let’s realise this one first, as common code
Three more entities to be modelled
-
Configuration: set of characters to be used to parse / represent CSV files- e.g. separator, delimiter, comment, etc.
-
Formatter: convertsRowsinto strings, according to someConfiguration -
Parser: converts some source into aTable, according to someConfiguration- source $\approx$ anything that can be interpreted as a string to be parsed (e.g. file, string, etc.)
@startuml skinparam monochrome false
package “io github gciatto csv” {
class Configuration {
+ separator: Char
+ delimiter: Char
+ comment: Char
--
+ isComment(string: String): Boolean
+ isRecord(string: String): Boolean
+ isHeader(string: String): Boolean
..
+ getComment(string: String): String?
+ getFields(string: String): List<String>
+ getColumnNames(string: String): List<String>
}
interface Formatter {
+ source: Iterable<Row>
+ configuration: Configuration
+ format(): Iterable<String>
}
interface Parser {
+ source: Any
+ configuration: Configuration
+ parse(): Iterable<Row>
}
Formatter "1" o-- "1" Configuration
Parser "1" o-- "1" Configuration
} @enduml
The Configuration class
data class Configuration(val separator: Char, val delimiter: Char, val comment: Char) {
// Checks whether the given string is a comment (i.e. starts with the comment character).
fun isComment(string: String): Boolean = // ...
// Gets the content of the comment line (i.e. removes the initial comment character).
fun getComment(string: String): String? = // ...
// Checks whether the given string is a record (i.e. it contains the delimiter character)
fun isRecord(string: String): Boolean = // ...
// Retrieves the fields in the given record (i.e. splits the string at the separator character)
fun getFields(string: String): List<String> = // ...
// Checks whether the given string is a header (i.e. simultaneously a record and a comment)
fun isHeader(string: String): Boolean = // ...
// Retrieves the column names in the given header
fun getColumnNames(string: String): List<String> = // ...
}
- implementation of methods is long and boring, but straightforward
- it relies on regular expressions, which are supported by Kotlin’s common std-lib
- details here
The Formatter interface
interface Formatter {
// The source of this formatter (i.e. the rows to be formatted).
val source: Iterable<Row>
// The configuration of this formatter (i.e. the characters to be used).
val configuration: Configuration
// Formats the source of this formatter into a sequence of strings (one per each row in the source)
fun format(): Iterable<String>
}
The Parser interface
interface Parser {
// The source to be parsed by this parser (must be interpretable as string)
val source: Any
// The configuration of this parser (i.e. the characters to be used).
val configuration: Configuration
// Parses the source of this parser into a sequence of rows (one per each row in the source)
fun parse(): Iterable<Row>
}
Common implementation of novel entities
@startuml skinparam monochrome false
package “io github gciatto csv impl” {
class Configuration
interface Formatter
interface Parser
DefaultFormatter "1" o-- "1" Configuration
AbstractParser "1" o-- "1" Configuration
class DefaultFormatter {
+ constructor(source: Iterable<Row>, configuration: Configuration)
- formatRow(row: Row): String
- formatAsHeader(row: Row): String
- formatAsRecord(row: Row): String
}
Formatter <|-- DefaultFormatter
abstract class AbstractParser {
# constructor(source: Any, configuration: Configuration)
# beforeParsing()
# afterParsing()
# {abstract} sourceAsLines(): Sequence<String>
}
Parser <|-- AbstractParser
class StringParser {
+ source: String
+ constructor(source: String, configuration: Configuration)
+ sourceAsLines(): Sequence<String>
}
AbstractParser <|-- StringParser
} @enduml
The DefaultFormatter class
class DefaultFormatter(override val source: Iterable<Row>, override val configuration: Configuration) : Formatter {
// Lazily converts each row from the source into a string, according to the configuration.
override fun format(): Iterable<String> = source.asSequence().map(this::formatRow).asIterable()
// Converts the given row into a string, according to the configuration.
private fun formatRow(row: Row): String = when (row) {
is Header -> formatAsHeader(row)
else -> formatAsRecord(row)
}
// Formats the given row as a header (putting the comment character at the beginning).
private fun formatAsHeader(row: Row): String = "${configuration.comment} ${formatAsRecord(row)}"
// Formats the given row as a record (using the separator and delimiter characters accordingly).
private fun formatAsRecord(row: Row): String =
row.joinToString("${configuration.separator} ") {
val delimiter = configuration.delimiter
"$delimiter$it$delimiter"
}
}
The AbstractParser class
class AbstractParser(override val source: Any, override val configuration: Configuration) : Parser {
// Empty methods to be overridden by sub-classes to initialize/finalise parsing.
protected open fun beforeParsing() { /* does nothing by default */ }
protected open fun afterParsing() { /* does nothing by default */ }
// Template method that parses the source into a sequence of strings (one per line).
protected abstract fun sourceAsLines(): Sequence<String>
// Parses the source into a sequence of rows (skipping comments, looking for at most 1 header).
override fun parse(): Iterable<Row> = sequence {
beforeParsing()
var header: Header? = null
var i = 0
for (line in sourceAsLines()) {
if (line.isBlank()) {
continue
} else if (configuration.isHeader(line)) {
if (header == null) {
header = headerOf(configuration.getColumnNames(line))
yield(header)
}
} else if (configuration.isComment(line)) {
continue
} else if (configuration.isRecord(line)) {
val fields = configuration.getFields(line)
if (header == null) {
header = anonymousHeader(fields.size)
yield(header)
}
try {
yield(recordOf(header, fields))
} catch (e: IllegalArgumentException) {
throw IllegalStateException("Invalid CSV at line $i: $line", e)
}
} else {
error("Invalid CSV line at $i: $line")
}
i++
}
afterParsing()
}.asIterable()
}
The StringParser class
class StringParser(override val source: String, configuration: Configuration)
: AbstractParser(source, configuration) {
// Splits the source string into lines.
override fun sourceAsLines(): Sequence<String> = source.lineSequence()
}
Providing functionalities via extension methods
-
Additions to the
Csv.ktfile:const val DEFAULT_SEPARATOR = ',' const val DEFAULT_DELIMITER = '"' const val DEFAULT_COMMENT = '#' // Converts the current container of rows into a CSV string, using the given characters. fun Iterable<Row>.formatAsCSV( separator: Char = DEFAULT_SEPARATOR, delimiter: Char = DEFAULT_DELIMITER, comment: Char = DEFAULT_COMMENT ): String = DefaultFormatter(this, Configuration(separator, delimiter, comment)).format().joinToString("\n") // Parses the current CSV string into a table, using the given characters. fun String.parseAsCSV( separator: Char = DEFAULT_SEPARATOR, delimiter: Char = DEFAULT_DELIMITER, comment: Char = DEFAULT_COMMENT ): Table = StringParser(this, Configuration(separator, delimiter, comment)).parse().let(::tableOf)
Unit tests and usage examples (pt. 1)
- Dummy instances for testing:
object CsvStrings { val iris: String = """ |# sepal_length, sepal_width, petal_length, petal_width, class |5.1,3.5,1.4,0.2,Iris-setosa |4.9,3.0,1.4,0.2,Iris-setosa |4.7,3.2,1.3,0.2,Iris-setosa """.trimMargin() val irisWellFormatted: String = """ |# "sepal_length", "sepal_width", "petal_length", "petal_width", "class" |"5.1", "3.5", "1.4", "0.2", "Iris-setosa" |"4.9", "3.0", "1.4", "0.2", "Iris-setosa" |"4.7", "3.2", "1.3", "0.2", "Iris-setosa" """.trimMargin() // other dummy constants here }
Unit tests and usage examples (pt. 2)
-
Tests involving parsing be like:
@Test fun parsingFromCleanString() { val parsed: Table = CsvStrings.iris.parseAsCSV() assertEquals( expected = Tables.iris(Tables.irisShortHeader), actual = parsed ) } -
Tests involving formatting be like:
@Test fun formattingToString() { val iris: Table = Tables.iris(Tables.irisShortHeader) assertEquals( expected = CsvStrings.irisWellFormatted, actual = iris.formatAsCSV() ) }
Time to go platform-specific
-
Further additions to the
Csv.ktfile:// Reads and parses a CSV file from the given path, using the given characters. expect fun parseCsvFile( path: String, separator: Char = DEFAULT_SEPARATOR, delimiter: Char = DEFAULT_DELIMITER, comment: Char = DEFAULT_COMMENT ): Table- notice the
expectkeyword, and the lack of function body - we’re just declaring the signature of a platform-specific function
- there is no type for representing paths is Kotlin’s common std-lib
- hence we’re using
Stringas a platform-agnostic representation of paths- this is suboptimal choice
- hence we’re using
- notice the
Time to go platform-specific on the JVM (pt. 1)
-
I/O (over textual files) is mainly supported by means of the following classes:
-
Buffered readers support reading a file line-by-line
-
On Kotlin/JVM, Java’s std-lib is available as Kotlin’s std-lib
- hence, we may use Java’s std-lib directly
- the abstraction gap is close to 0
-
We may simply create a new sub-type of
AbstractParser- using
Files as sources - creating a
BufferedReaderbehind the scenes to read files line-by-line
- using
Time to go platform-specific on the JVM (pt. 2)
In the jvmMain source set
-
let’s define the following JVM-specific class:
class FileParser( override val source: File, // source is now forced to be a File configuration: Configuration ) : AbstractParser(source, configuration) { // Lately initialised reader, corresponding to source private lateinit var reader: BufferedReader // Opens the source file, hence initialising the reader, before each parsing override fun beforeParsing() { reader = source.bufferedReader() } // Closes the reader, after each parsing override fun afterParsing() { reader.close() } // Lazily reads the source file line-by-line override fun sourceAsLines(): Sequence<String> = reader.lines().asSequence() } -
let’s create the
Csv.jvm.ktfile containing:actual fun parseCsvFile( path: String, separator: Char, delimiter: Char, comment: Char ): Table = FileParser(File(path), Configuration(separator, delimiter, comment)).parse().let(::tableOf)- this is how the
parseCsvFileis implemented on the JVM - notice the
actualkeyword, and the presence of a function body - notice the usage of
FileParserin the function body- class
FileParseris internal class for filling the abstraction gap on the JVM
- class
- this is how the
Time to go platform-specific on the JS (pt. 1)
-
I/O (over textual files) is mainly supported by means of the following things:
-
These function supports reading / writing a file in one shot
- i.e. they return / generate the whole content of the file as a string
- quite inefficient if the file is big
-
On Kotlin/JS, Node’s std-lib is not directly available
- one must instruct the compiler about
- where to look up for std-lib function (module name)
- how to map JS functions to Kotlin functions (
externaldeclarations)
- the abstraction gap is non-negligible
- one must instruct the compiler about
-
To-do list for Kotlin/JS:
- create
externaldeclarations for the Node’s std-lib functions to be used - implement JS-specific code via the
StringParser(after reading the whole file)
- create
Time to go platform-specific on the JS (pt. 2)
In the jsMain source set
-
let’s create the
NodeFs.ktfile (containingexternaldeclarations for thefsmodule):@file:JsModule("fs") @file:JsNonModule package io.github.gciatto.csv // Kotlin mapping for: https://nodejs.org/api/fs.html#fsreadfilesyncpath-options external fun readFileSync(path: String, options: dynamic = definedExternally): String // Kotlin mapping for: https://nodejs.org/api/fs.html#fswritefilesyncfile-data-options external fun writeFileSync(file: String, data: String, options: dynamic = definedExternally)- the
@JsModuleannotation instructs the compiler about where to look up for thefsmodule externaldeclarations are Kotlin signatures of JS functiondynamicis a special type that can be used to represent any JS object- it overrides Kotlin’s type system, hence it should be used with care
- it prevents developers from declaring too much
externalstuff - good to use when the JS API is not known in advance or uses union types
definedExternallyis stating that a parameter is optional (default value is defined in JS)
- the
Time to go platform-specific on the JS (pt. 3)
-
let’s create the
Csv.js.ktfile containing:actual fun parseCsvFile( path: String, separator: Char, delimiter: Char, comment: Char ): Table = readFileSync(path, js("{encoding: 'utf8'}")).parseAsCSV(separator, delimiter, comment)- this is how the
parseCsvFileis implemented on JS - notice the
actualkeyword, and the presence of a function body - notice the usage of
readFileSyncto read a file as a string in one shot - notice the exploitation of common code for parsing the string into a
Table(namely,parseAsCSV) - notice the
js("...")magic function- it allows to write JS code directly in Kotlin
- the provided string should contain bare JS code, the compiler will output “as-is”
- it’s a way to fill the abstraction gap on JS
- we use it to create a JS object on the fly, to provide optional parameters to
readFileSync
- this is how the
Platform-agnostic testing (strategy)
-
We may test our CSV library in common-code
- so as to avoid repeating testing code
-
The test suite may:
- create temporary files with known paths, containing known CSV data
- read those paths, and parse them as CSV
- assert that the parsed tables are as expected
-
The hard part is step 1: two platform-specific steps
- discovering the temp directory of the current system
- writing a file
Multi-platform testing (preliminaries)
-
file
Utils.ktincommonTest:// Creates a temporary file with the given name, extension, and content, and returns its path. expect fun createTempFile(name: String, extension: String, content: String): Stringnotice the
expected function -
file
Utils.jvm.ktinjvmTest:import java.io.File actual fun createTempFile(name: String, extension: String, content: String): String val file = File.createTempFile(name, extension) file.writeText(content) return file.absolutePath }- cf. documentation of method
File.createTempFile
- cf. documentation of method
-
file
Utils.js.ktinjsTest:private val Math: dynamic by lazy { js("Math") } @JsModule("os") @JsNonModule external fun tmpdir(): String actual fun createTempFile(name: String, extension: String, content: String): String { val tag = Math.random().toString().replace(".", "") val path = "$tmpDirectory/$name-$tag.$extension" writeFileSync(path, content) return path }
Multi-platform testing (actual tests)
-
file
CsvFiles.ktincommonMain:object CsvFiles { // Path of the temporary file containing the string CsvStrings.iris // (file lazily created upon first usage). val iris: String by lazy { createTempFile("iris.csv", CsvStrings.iris) } // Path of the temporary file containing the string CsvStrings.irisWellFormatted // (file lazily created upon first usage). val irisWellFormatted: String by lazy { createTempFile("irisWellFormatted.csv", CsvStrings.irisWellFormatted) } // other paths here, corresponding to other constants in CsvStrings } -
tests for parsing be like:
@Test fun testParseIris() { val parsedFromString = CsvStrings.iris.parseAsCSV() val readFromFile = parseCsvFile(CsvFiles.iris) assertEquals(parsedFromString, readFromFile) }
Output of a multi-platform build
-
Kotlin multi-platform projects can be assembled as JARs
- enabling importing the project as dependency in other multi-platform projects
-
The
jvmMainsource set is compiled into a JVM-compliant JARs- enabling importing the project as dependency in JVM projects
- enabling the creation of runnable JARs
- via the various
*Jarorassembletasks
-
The
jsMainsource set is compiled into either- a Kotlin library (
.klib), enabling importing the project as dependency in Kotlin/JS projects- via the various
*Jarorassembletasks
- via the various
- a NodeJS project
- via the
compileProductionExecutableKotlinJstask
- via the
- a Kotlin library (
Output of JVM compilation
-
Task for JVM-only compilation of re-usable packages:
jvmJar -
Effect:
- compile the project as JVM bytecode
- pack the bytecode into a JAR file
- move the JAR file into
$PROJ_DIR/build/libs/$PROJ_NAME-jvm-$PROJ_VERSION
-
The JAR does not contain dependencies
-
Ad-hoc Gradle plugins/code is needed for creating fat Jar
Output of JS compilation
-
Task for JS-only compilation of re-usable packages:
compileProductionExecutableKotlinJs -
Effect:
- Generate Node project into
$ROOT_PROJ_DIR/build/js/packages/$ROOT_PROJ_NAME-$PROJ_NAME:- JS code
package.jsonfile
- Dead code elimination (DCE) removing unused code
- i.e. code not (indirectly) called by main
- Generate Node project into
-
Support for packing as NPM package via the
npm-publishGradle plugin
Calling Kotlin from other platforms
-
Kotlin code can be called from the target platforms’ main languages
- e.g. Java, JavaScript, etc.
-
Understanding the mapping among Kotlin and other languages is key
- it impacts the usability of Kotlin libraries for ordinary platform users
How are Kotlin’s syntactical categories mapped to other platforms/languages?
- the answer varies on a per-platform basis
Kotlin–Java Mapping (pt. 1)
- Kotlin class $\equiv$ Java class
class MyClass {}
interface MyType {}
public class MyClass {}
public interface MyType {}
- No syntactical difference among primitive and reference types
Int$\leftrightarrow$int/Integer,Short$\leftrightarrow$short/Short, etc.
val x: Int = 0
val y: Int? = null
int x = 0;
Integer y = null;
- Some Kotlin types are replaced by Java types at compile time
- e.g.
Any$\rightarrow$Object,kotlin.collections.List$\rightarrow$java.util.List, etc.
- e.g.
val x: Any = "ciao"
val y: kotlin.collections.List<Int> = listOf(1, 2, 3)
val z: kotlin.collections.MutableList<String> = mutableListOf("a", "b", "c")
Object x = "ciao";
java.util.List<Integer> y = java.util.Arrays.asList(1, 2, 3);
java.util.List<String> z = java.util.List.of("a", "b", "c");
- Other Kotlin types are mapped to homonymous Java types
Kotlin–Java Mapping (pt. 2)
- Kotlin properties are mapped to getter / setter methods
interface MyType {
val x: Int
var y: String
}
public interface MyType {
int getX();
String getY(); void setY(String y);
}
- … unless the
JvmFieldannotation is adopted
import kotlin.jvm.JvmField
class MyType {
@JvmField
val x: Int = 0
@JvmField
var y: String = ""
}
public class MyType {
public final int x = 0;
public String y = "";
}
- Kotlin’s package functions in file
X.ktare mapped to static methods of classXKt
// file MyFile.kt
fun f() {}
public static class MyFileKt {
public static void f() {}
}
- … unless the
JvmNameannotation is exploited
@file:JvmName("MyModule")
import kotlin.jvm.JvmName
fun f() {}
public class MyModule {
public static void f() {}
}
Kotlin–Java Mapping (pt. 3)
- Kotlin’s
object Xis mapped to Java classXwith- private constructor
- public static final field named
INSTANCEto access
object MySingleton {}
public static class MySingleton {
private MySingleton() {}
public static final MySingleton INSTANCE = new MySingleton();
}
- Class
X’s companion object is mapped to public static final field namedCompanionon classX
class MyType {
private constructor()
companion object {
fun of(): MyType = MyType()
}
}
// usage:
val x: MyType = MyType.of()
public class MyType {
private MyType() {}
public static final class Companion {
public MyType of() { return new MyType(); }
}
public static final Companion Companion = new Companion();
}
// usage:
MyType x = MyType.Companion.of();
Kotlin–Java Mapping (pt. 4)
- Class
X’s companion object’s memberMtagged with@JvmStaticis mapped to static memberMon classX
import kotlin.jvm.JvmStatic
class MyType {
private constructor()
companion object {
@JvmStatic
fun of(): MyType = MyType()
}
}
// usage:
val x: MyType = MyType.of()
public class MyType {
private MyType() {}
public static MyType of() { return new MyType(); }
}
// usage:
MyType x = MyType.of();
- Kotlin’s variadic functions are mapped to Java’s variadic methods
fun f(vararg xs: Int) {
val ys: Array<Int> = xs
}
void f(int... xs) {
Integer[] ys = xs;
}
- Kotlin’s extension methods are mapped to ordinary Java methods with one more argument
class MyType { }
fun MyType.myMethod() {}
// usage:
val x = MyType()
x.myMethod() // postfix
public class MyType {}
public void myMethod(MyType self) {}
// usage:
MyType x = new MyType();
myMethod(x); // prefix
Kotlin–Java Mapping (pt. 5)
- practical consequence: usability of fluent chains, in Java, is suboptimal
- e.g. sequence operations are implemented as extension methods
import kotlin.sequences.*
val x = (0 ..< 10).asSequence() // 0, 1, 2, ..., 9
.filter { it % 2 == 0 } // 0, 2, 4, ..., 8
.map { it + 1 } // 1, 3, 5, ..., 9
.sum() // 25
import static kotlin.sequences.SequencesKt.*;
int x = sumOfInt(
map(
filter(
asSequence(
new IntRange(0, 9).iterator()
),
it -> it % 2 == 0
),
it -> it + 1
)
);
- optional arguments exist in Kotlin but they do not exist in Java
fun f(a: Int = 1, b: Int = 2, c: Int = 3) = // ...
// usage:
f(b = 5)
void f(int a, int b, int c) { /* ... */ }
// usage:
f(1, 5, 3);
Kotlin–Java Mapping (pt. 6)
- practical consequence:
- arguments are handy in Kotlin, but…
- … they are painful to use in Java
- mitigation strategy: use
@JvmOverloadsto generate overloaded methods for Java- sadly, the does not take into account all possible ordered combinations of arguments
import kotlin.jvm.JvmOverloads
@JvmOverloads
fun f(a: Int = 1, b: Int = 2, c: Int = 3) = // ...
void f(int a, int b, int c) { /* ... */ }
void f(int a, int b) { f(a, b, 3); }
void f(int a) { f(a, 2, 3); }
void f() { f(1, 2, 3); }
// missing overloads:
// void f(int a, int c) { f(a, 2, c); }
// void f(int b, int c) { f(1, b, c); }
// void f(int c) { f(1, 2, c); }
// void f(int b) { f(1, b, 3); }
Kotlin–Java Mapping Example
-
Compile our CSV lib and import it as a dependency in a novel Java library
-
Alternatively, add Java sources to the
jvmTestsource set, and use the library -
Listen to the teacher presenting key points
Kotlin–JavaScript Mapping (pt. 1)
Disclaimer: the generated JS code is not really meant to be read by humans
- DCE will eliminate unused code
- “unused” $\equiv$ “not explicitly labelled as exported”
- code is exported by means of the
@JsExportannotation- to be used on API types and functions
- requires the
kotlin.js.ExperimentalJsExportopt-in
- not all syntactical constructs or types are currently exportable
- you should ignore the warning explicitly
@file:Suppress("NON_EXPORTABLE_TYPE")
package my.package
import kotlin.js.JsExport
import kotlin.js.JsName
@JsExport
class MyType {
val nonExportableType: Long
}
@JsExport
fun myFunction() = // ...
var module = require("project-name");
var MyType = module.my.package.MyType;
var myFunction = module.my.package.myFunction;
Kotlin–JavaScript Mapping (pt. 2)
- Kotlin supports overloading, JS does not
- class / interface members names are mengled to avoid clashes
- the
@JsNameannotation can be used to control the name of a member- to be used on API types and functions
package my.package
@JsName("sumNumbers")
fun sum(vararg numbers: Int): Int = // ...
@JsName("sumIterableOfNumbers")
fun sum(numbers: Iterable<Int>): Int = // ...
@JsName("sumSequenceOfNumbers")
fun sum(numbers: Sequence<Int>): Int = // ...
var module = require("project-name");
var sumNumbers = module.my.package.sumNumbers;
var sumIterableOfNumbers = module.my.package.sumIterableOfNumbers;
var sumSequenceOfNumbers = module.my.package.sumSequenceOfNumbers;
- Kotlin class $\equiv$ JS prototype
class MyClass(private val argument: String) {
@JsName("method")
fun method(): String = argument + "!"
}
function MyClass(argument) {
this.randomName_1 = argument
}
MyClass.prototype.method = function () {
return this.randomName_1 + "!"
}
Kotlin–JavaScript Mapping (pt. 3)
- Primitive type mappings are non-trivial (cf. documentation)
-
Kotlin numeric types, except for
kotlin.Long, are mapped to JavaScriptNumber -
kotlin.Charis mapped to JSNumberrepresenting character code. -
Kotlin preserves overflow semantics for
kotlin.Int,kotlin.Byte,kotlin.Short,kotlin.Charandkotlin.Long -
kotlin.Longis not mapped to any JS object, as there is no 64-bit integer number type in JS. It is emulated by a Kotlin class -
kotlin.Stringis mapped to JSString -
kotlin.Anyis mapped to JSObject(new Object(),{}, and so on) -
kotlin.Arrayis mapped to JSArray -
Kotlin collections (
List,Set,Map, and so on) are not mapped to any specific JS type -
kotlin.Throwableis mapped to JSError
-
Kotlin–JavaScript Mapping (pt. 4)
-
practical consequence: no way to distinguish numbers by type
val x: Int = 23 val y: Any = x println(y as Float) // fails on JVM, works on JS -
Kotlin’s
dynamicoverrides the type system, and it is translated “1-to-1”
val string1: String = "some string"
string1.missingMethod() // compilation error
val string2: dynamic = "some string"
string2.missingMethod() // compilation ok, runtime error
- Kotlin’s common std-lib is implemented in JS
- cf. NPM package
kotlin
- cf. NPM package
Kotlin–JavaScript Mapping (pt. 5)
-
Companion objects are treated similarly to Kotlin/JVM
-
Extension methods are treated similarly to Kotlin/JVM
-
Variadic functions are compiled to JS functions accepting an array
- which are not really variadic in JS
fun f(vararg xs: String) = // ...
// usage:
f("a")
f("a", "b")
f("a", "b", "c")
// usage:
f(["a"])
f(["a", "b"])
f(["a", "b", "c"])
Multi-platform CI/CD
Conceptual workflow:
- Check style (e.g. via KtLint) of all Kotlin sources
- Automatic bug detection (e.g. via Detekt)
- For each operative system
O(e.g. Win, Mac, Linux):- for each target platform
T:- for each relevant version
Vof the platformT(e.g. LTS releases + latest)- ensure main code compiles (e.g. via Gradle task
<T>MainClasses) - ensure test code compiles (e.g. via Gradle task
<T>TestClasses) - ensure test passes (e.g. via Gradle task
<T>Test)
- ensure main code compiles (e.g. via Gradle task
- for each relevant version
- for each target platform
- If need to release (e.g. commit on
masterbranch)- for each target platform
T$\cup$kotlin-multiplatform:- assemble compiled code into archive
- push archive on main repository
Rof platformT
- for each target platform
About the practical CI/CD
-
Even more complicated, because release on Maven Central is complex
-
Setting up a CI/CD pipeline of this kind requires a lot of work
- and Gradle / GitHub Actions boilerplate
-
Recommendations:
- Use templates, such as: https://github.com/gciatto/template-kt-mpp-project/
- Use Gradle plugins, such as: https://github.com/gciatto/kt-mpp
- Use existing projects as examples, e.g. https://github.com/tuProlog/2p-kt
Repositories by platform (pt. 1)
Takeaway: each platform has some preferred main repository where users expect to find packages onto
-
JVM$\rightarrow$ Maven Central Repository (MCR)- other Maven repositories exist, but they are more fragile
-
Kotlin / Multiplatform $\rightarrow$ MCR
-
JS$\rightarrow$ NPM -
Android$\rightarrow$ Google Play -
Mac/iOS$\rightarrow$ App Store- or Homebrew
Repositories by platform (pt. 2)
-
Windows$\rightarrow$ Microsoft Store- or Chocolatey
- or Scoop
-
Linux$\rightarrow$ depends on the distro- e.g. Arch Linux $\rightarrow$ AUR
- inter-distro: Flatpack $\rightarrow$ Flathub
-
Python$\rightarrow$ PyPI -
.Net$\rightarrow$ NuGet
Multi-platform programming
Write first, wrap elsewhere
Write first, wrap elsewhere: the case of JPype
-
In the end of the day, the Python interpreter is C++ software
-
Most commonly, efficient Python code is written in C++ and then wrapped into Python
-
Put it simply, the JVM too is C++ software
-
Can Python code be written in Java and then wrapped into Python?
-
Apparently yes, via several ad-hoc bridging technologies:
-
Why exactly JPype?
- still maintained, works with vanilla CPython, good documentation, good interoperabilty with JVM types
JPype Overview:
-
Ensure you have a JVM installed on your system
- with the
JAVA_HOMEenvironment variable set to the JVM installation directory
- with the
-
Ensure your compiled Java code is available as a
.jarfile- say, in
/path/to/my.jar
- say, in
-
Install the JPype package via
pip install JPype1 -
You first need JPype to start a JVM instance in your Python process
- tby default, JVM location is inferred from the
JAVA_HOMEenvironment variable
import jpype # start the JVM jpype.startJVM(classpath=["/path/to/my.jar"]) - tby default, JVM location is inferred from the
-
Once the JVM is started, one can import Java classes and call their methods as if they were Python objects
import jpype.imports # this is necessary to import Java classes from java.lang import System # import the java.lang.System class System.out.println("Hello World!")
JPype’s Bridging Model (pt. 1)
Overview on the official documentation
-
Java classes are presented wherever possible similar to Python classes
-
the only major difference is that Java classes and objects are closed and cannot be modified
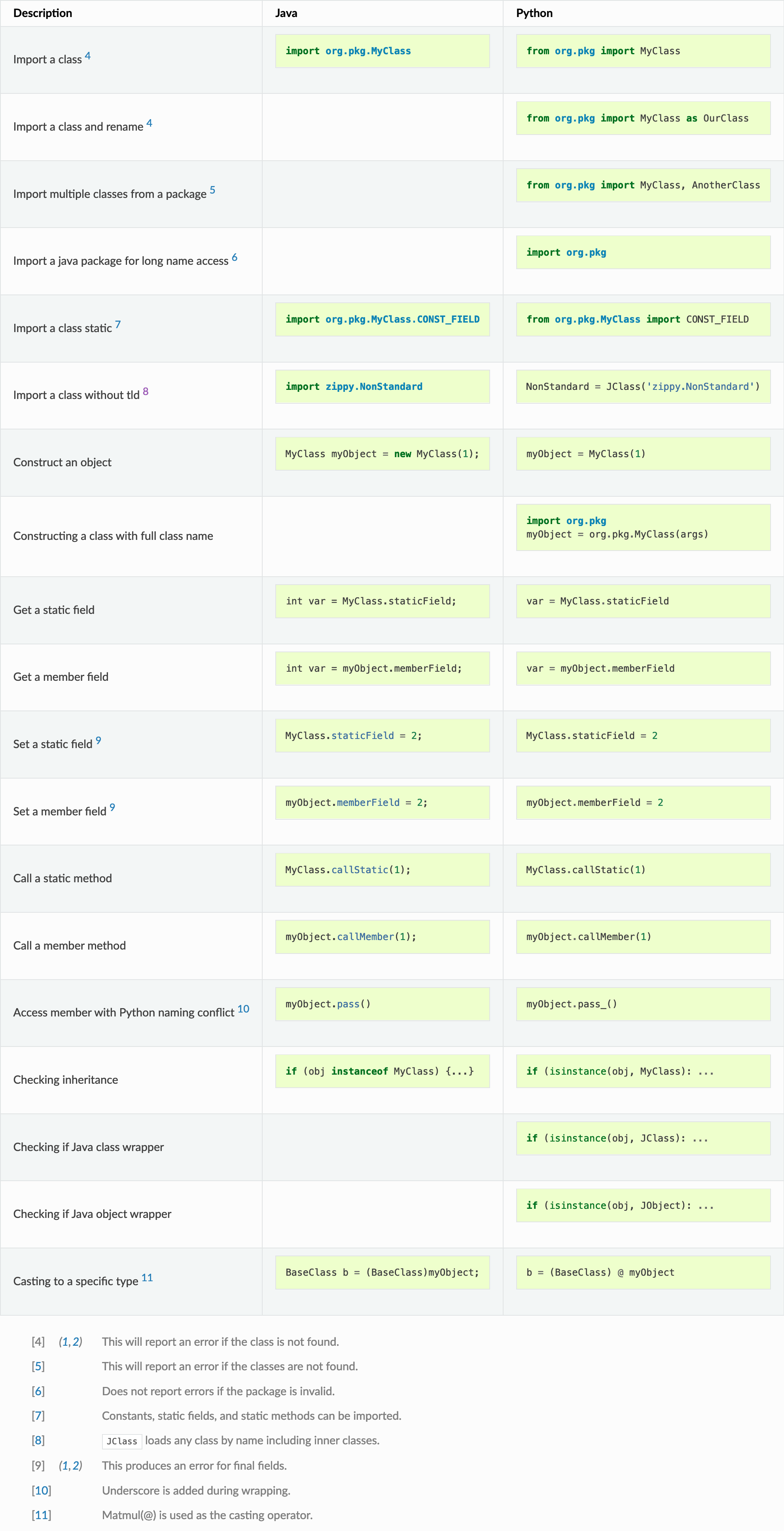
JPype’s Bridging Model (pt. 2)
Overview on the official documentation
-
Java exceptions extend from Python exceptions
-
Java exceptions can be dealt with in the same way as Python native exceptions
- i.e. via
try-exceptblocks
- i.e. via
-
JExceptionserves as the base class for all Java exceptions
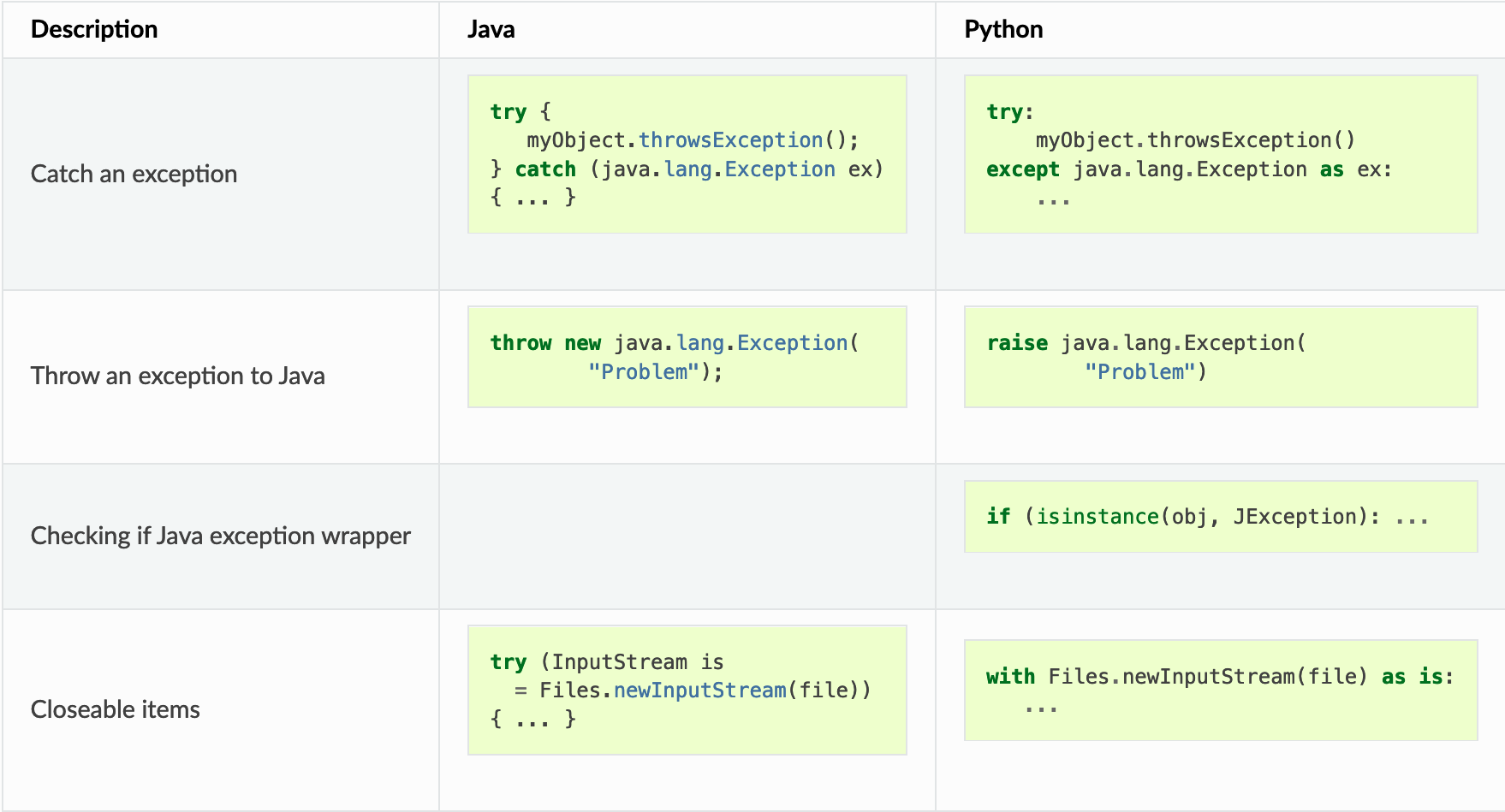
JPype’s Bridging Model (pt. 3)
Overview on the official documentation
-
most Python primitives directly map into Java primitives
-
however, Python does not have the same primitive types…
-
… hence, explicit casts may be needed in some cases
-
each primitive Java type is exposed in JPype (
jpype.JBoolean,.JByte,.JChar,.JShort,.JInt,.JLong,.JFloat,.JDouble).
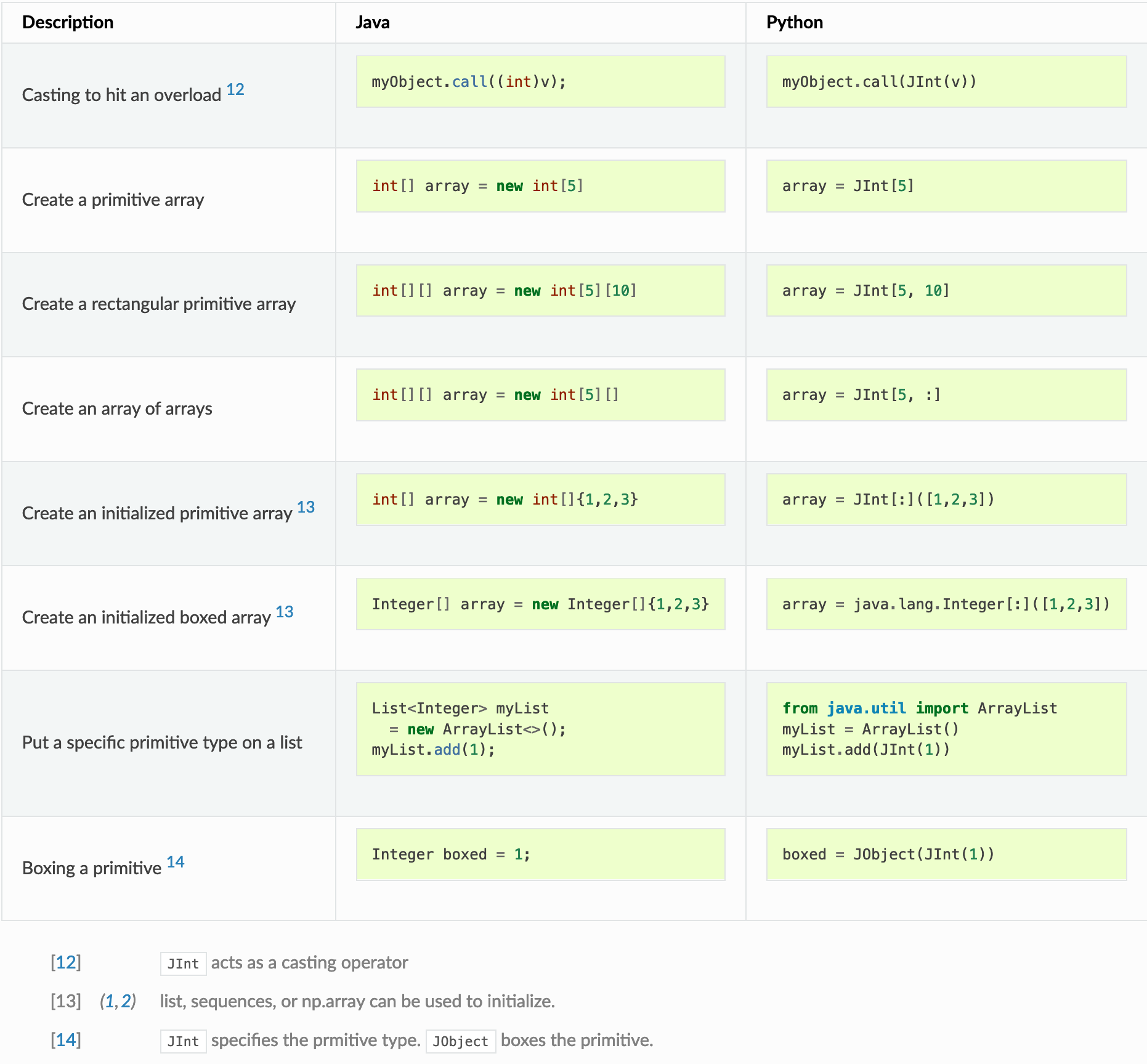
JPype’s Bridging Model (pt. 4)
Overview on the official documentation
-
Java strings are similar to Python strings
-
they are both immutable and produce a new string when altered
-
most operations can use Java strings in place of Python strings
- with minor exceptions, as Python strings are not completely duck typed
-
when comparing or using strings as dictionary keys, all
JStringobjects should be converted to Python
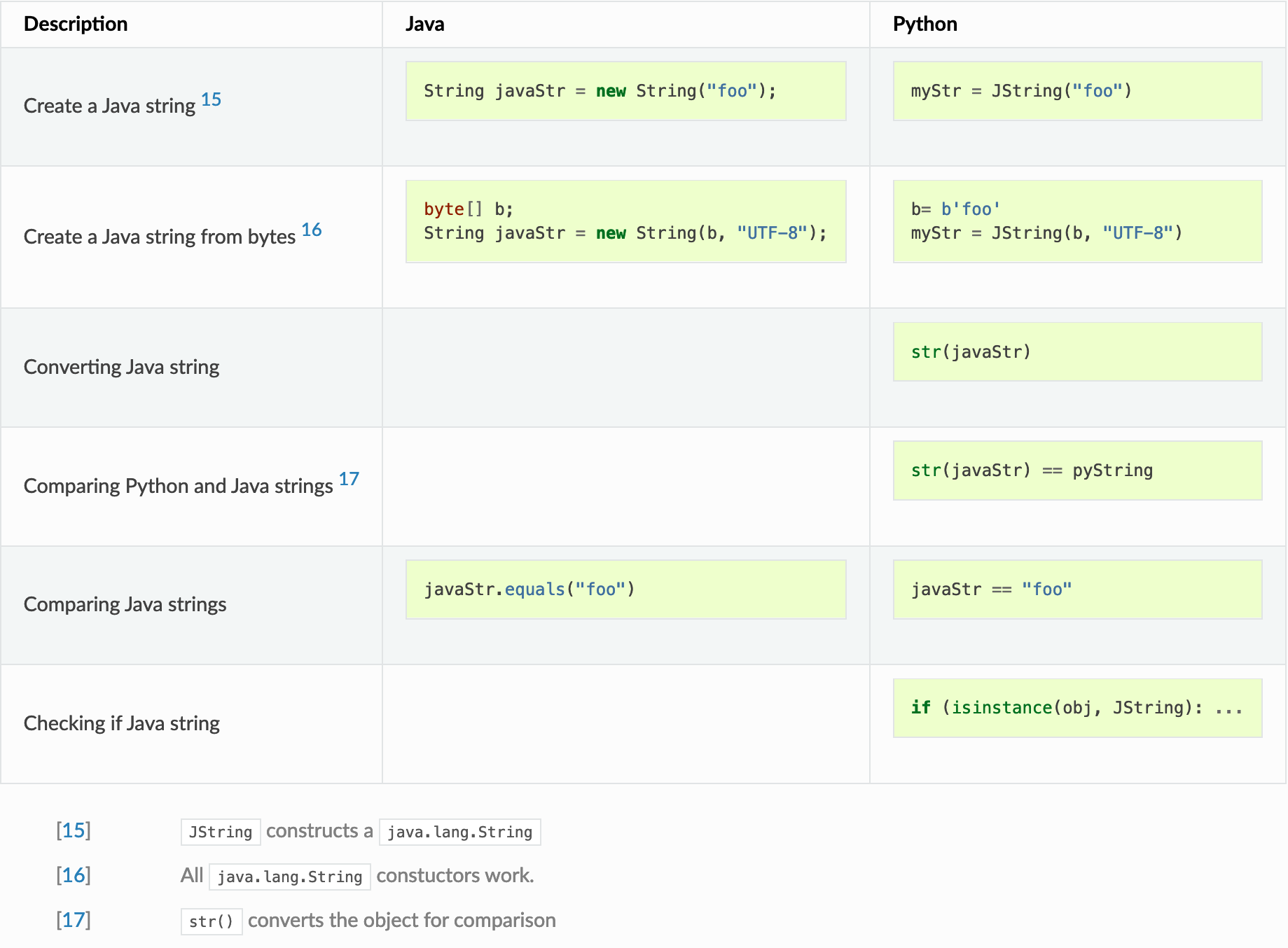
JPype’s Bridging Model (pt. 5)
Overview on the official documentation
-
Java arrays are mapped to Python lists
-
more precisely, they operate like Python lists, but they are fixed in size
-
reading a slice from a Java array returns a view of the array, not a copy
-
passing a slide of a Python list to Java will create a copy of the sub-list
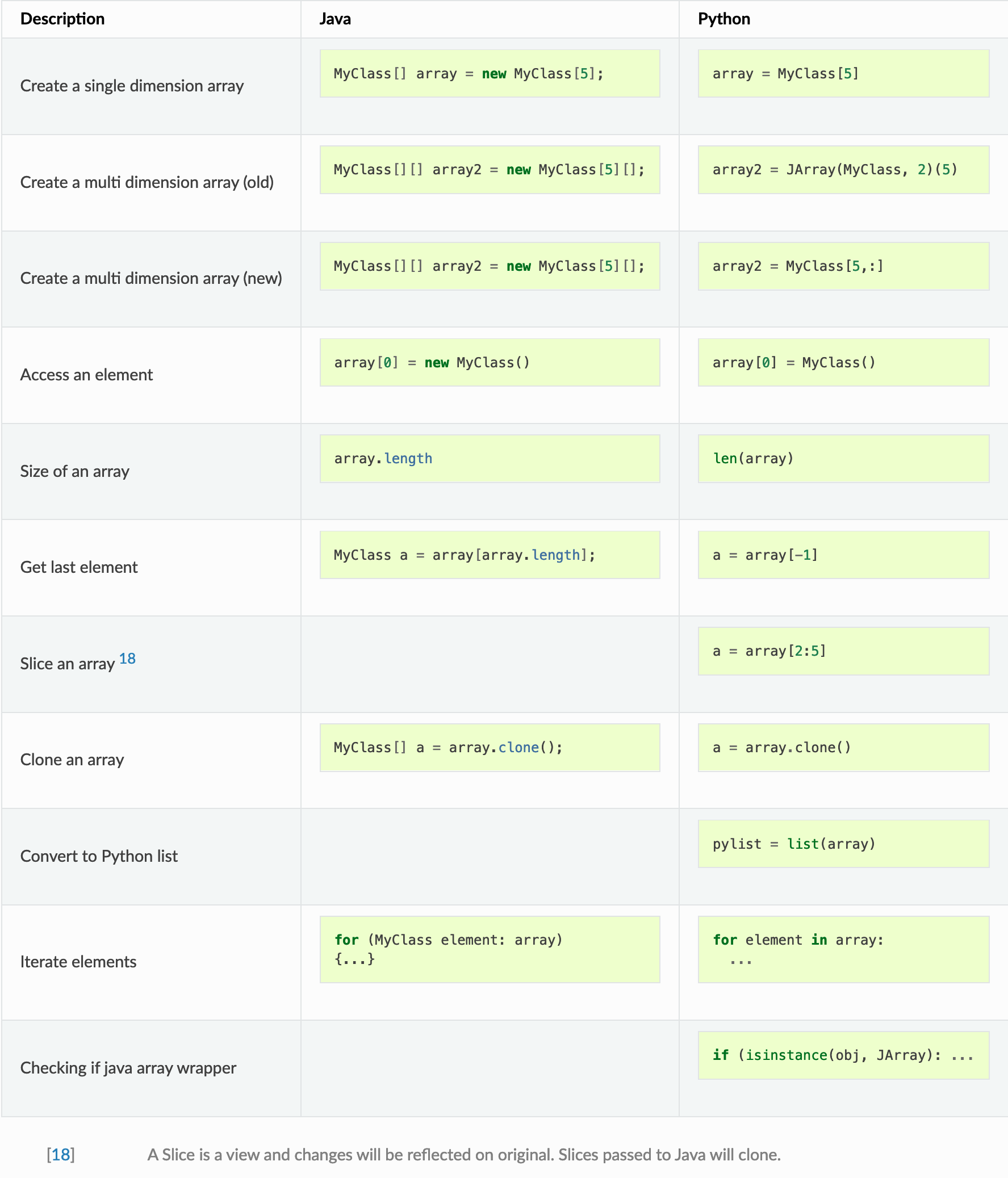
JPype’s Bridging Model (pt. 6)
Overview on the official documentation
-
Java collections are overloaded with Python syntax where possible
- to operate similarly to Python collections
-
Java’s
Iterables are mapped to Python iterables by overriding the__iter__method -
Java’s
Collections are mapped to Python containers by overriding__len__ -
Java’s
Maps support Python’s dictionaries syntax by overriding__getitem__and__setitem__ -
Java’s
Lists support Python’s lists syntax by overriding__getitem__and__setitem__
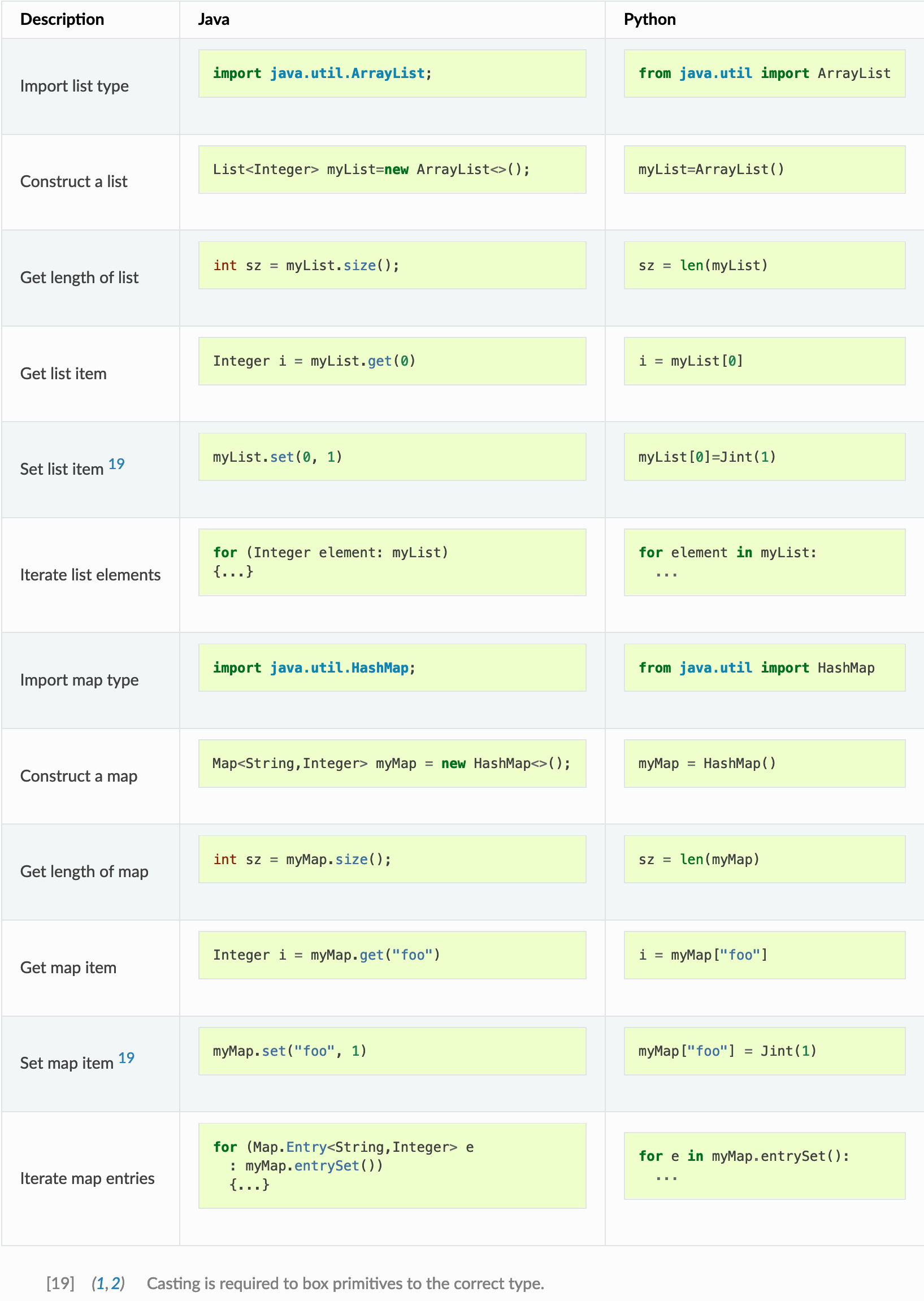
JPype’s Bridging Model (pt. 7)
Overview on the official documentation
-
Java interfaces can be implemented in Python, via JPype’s decorators
-
Java’s open / abstract classes cannot be extended in Python
-
Python lambda expressions can be cast’d to Java’s functional interfaces

JPype type conversion model (pt. 1)
Overview on the official documentation
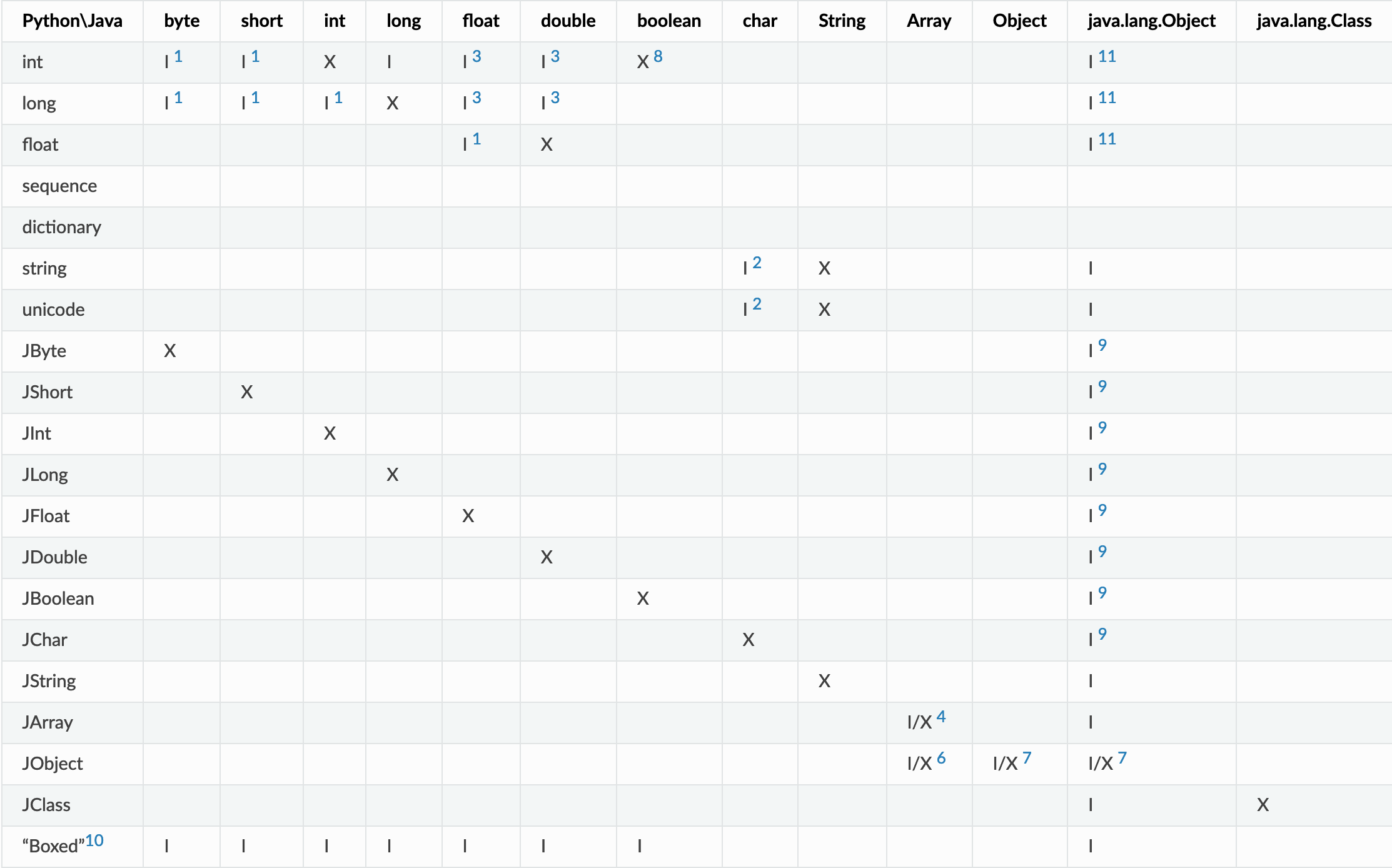
JPype type conversion model (pt. 2)
Legend
-
none, there is no way to convert
-
explicit (E), JPype can convert the desired type, but only explicitly via casting
-
implicit (I), JPype will convert as needed
-
exact (X), like implicit, but takes priority in overload selection
Overload selection
-
Consider the following example of Python code with JPype:
import jpype.imports from java.lang import System System.out.println(1) System.out.println(2.0) System.out.println('A') -
Which overload of
System.out.printlnis called among the many admissible ones?- Python’s
1is convertible to Java’sint,long, andshort- but Java’s
intis the exact match
- but Java’s
- Python’s
2.0is convertible to Java’sfloatanddouble- but Java’s
doubleis the exact match
- but Java’s
- Python’s
'A'is convertible to Java’sStringandchar- but Java’s
Stringis the exact match
- but Java’s
- Python’s
Ambiguous overload selection
-
Consider the following example of Python code with JPype:
import jpype csv = jpype.JPackage("io.github.gciatto.csv.Csv") csv.headerOf(["filed", "another field"]) -
This would raise the following error:
TypeError: Ambiguous overloads found for io.github.gciatto.csv.Csv.headerOf(list) between: public static final io.github.gciatto.csv.Header io.github.gciatto.csv.Csv.headerOf(java.lang.Iterable) public static final io.github.gciatto.csv.Header io.github.gciatto.csv.Csv.headerOf(java.lang.String[])- because Python’s
listis convertible to both Java’sIterableandString[]- but neither is the exact match
- because Python’s
-
To solve this issue, one can explicitly cast the Python
listto the desired Java type:import jpype import jpype.imports from java.lang import Iterable as JIterable csv = jpype.JClass("io.github.gciatto.csv.Csv") csv.headerOf(JIterable@["field", "another field"]) # returns Header("field", "another field")
Customising Java types in Python (pt. 1)
-
One may customise the behaviour of Java types in Python by providing custom implementations for them
- by means of the
@JImplementationFordecorator
- by means of the
-
In that case the special method
__jclass_init__is called on the custom implementation, just once, to configure the class -
In type hierarchies, implementations provided for superclasses are inherited by subclasses
Customising Java types in Python (pt. 2)
Consider for instance the following customisations, allowing to use Java collections with Python syntax
from typing import Iterable, Sequence
@jpype.JImplementationFor("java.lang.Iterable")
class _JIterable:
def __jclass_init__(self):
Iterable.register(self) # makes this class a subtype of Iterable, to speed up isinstance checks
def __iter__(self):
return self.iterator()
@jpype.JImplementationFor("java.util.Collection")
class _JCollection:
def __len__(self):
return self.size() # supports "len(coll)" syntax
def __delitem__(self, i):
return self.remove(i) # supports "del coll[i]" syntax
def __contains__(self, i):
return self.contains(i) # supports "i in coll" syntax
# __iter__ is inherited from _JIterable
# because in Java: Collection extends Iterable
@jpype.JImplementationFor('java.util.List')
class _JList(object):
def __jclass_init__(self):
Sequence.register(self) # makes this class a subtype of Sequence, to speed up isinstance checks
def __getitem__(self, ndx):
return self.get(ndx) # supports "list[i]" syntax
def append(self, obj):
return self.add(obj) # supports "list.append(obj)" syntax
# __len__, __delitem__, __contains__, __iter__ are inherited from _JCollection
this is taken directly from JPype’s codebase
Making wrapped code Pythonic (pt. 1)
-
The code wrapped via JPype is not Pythonic by default
- it works in principle, but it is very hard to use for the average Python developer
- we cannot assume the average Python developer is familiar with Java…
- nor with JPype
- and the developer should know both aspects to use the wrapped code as is
- it works in principle, but it is very hard to use for the average Python developer
-
It is important to make the wrapped code as Pythonic as possible
- factory methods for building instances of types
- simplified package structure
- e.g.
io.github.gciatto.csv.Csv$\rightarrow$jcsv.Csv
- e.g.
- properties instead of getters and setters
snake_caseinstead ofcamelCase- magic methods implemented whenever possible
- e.g.
__len__forjava.util.Collection - e.g.
__getitem__forjava.util.List
- e.g.
- optional parameters in methods instead of overloads
-
All such refinements can be done in JPype via customisations of the Java types
- unit tests should be written to ensure the customisations are not broken by future changes
Making wrapped code Pythonic (pt. 2)
Workflow
For all public types in the wrapped Java library:
- decide their corresponding Python package
- provide Pythonic factory methods
- customise the Python class to make it Pythonic (possibly exploiting type hierarchies to save time)
- add properties calling getters/setters
- override Java methods to make them Pythonic
- e.g. use magic methods where possible
- e.g. use optional parameters where possible, removing the need for overloads
- write unit tests for Pythonic API
Example: the jcsv package (pt. 1)
-
The
jcsvpackage is a Pythonic wrapper for our JVM-basedio.github.gciatto.csvlibrary -
Java’s type definition are brought to Python in
jcsv/__init__.py:import jpype import jpype.imports from java.lang import Iterable as JIterable _csv = jpype.JPackage("io.github.gciatto.csv") Table = _csv.Table Row = _csv.Row Record = _csv.Record Header = _csv.Header Formatter = _csv.Formatter Parser = _csv.Parser Configuration = _csv.Configuration Csv = _csv.Csv CsvJvm = _csv.CsvJvmmaking it possible to write the following code on the user side:
from jcsv import Table, Record, Header
Example: the jcsv package (pt. 2)
-
Parsing and formatting operations are mapped straightforwardly to Python functions:
# jcsv/__init__.py def parse_csv_string(string, separator = Csv.DEFAULT_SEPARATOR, delimiter = Csv.DEFAULT_DELIMITER, comment = Csv.DEFAULT_COMMENT): return Csv.parseAsCSV(string, separator, delimiter, comment) def parse_csv_file(path, separator = Csv.DEFAULT_SEPARATOR, delimiter = Csv.DEFAULT_DELIMITER, comment = Csv.DEFAULT_COMMENT): return CsvJvm.parseCsvFile(str(path), separator, delimiter, comment) def format_as_csv(rows, separator = Csv.DEFAULT_SEPARATOR, delimiter = Csv.DEFAULT_DELIMITER, comment = Csv.DEFAULT_COMMENT): return Csv.formatAsCSV(JIterable@rows, separator, delimiter, comment)
Example: the jcsv package (pt. 3)
-
Ad-hoc factory method is provided for building
Headerinstances:# jcsv/__init__.py from jcsv.python import iterable_or_varargs def header(*args): if len(args) == 1 and isinstance(args[0], int): return Csv.anonymousHeader(args[0]) return iterable_or_varargs(args, lambda xs: Csv.headerOf(JIterable@map(str, xs)))making it possible to write the following code on the user side:
import jcsv header1 = jcsv.header("column1", "column2", "column3") header2 = jcsv.header(3) # anonymous header with 3 columns columns = (f"column{i}" for i in range(1, 4)) # generator expression header3 = jcsv.header(columns) # same as header1, but passing an iterable -
Function
iterable_or_varargsaims at simulating multiple overloads:# jcsv/python.py from typing import Iterable def iterable_or_varargs(args, f): assert isinstance(args, Iterable) if len(args) == 1: item = args[0] if isinstance(item, Iterable): return f(item) else: return f([item]) else: return f(args)
Example: the jcsv package (pt. 4)
-
Ad-hoc factory method is provided for building
Recordinstances:# jcsv/__init__.py def record(header, *args): return iterable_or_varargs(args, lambda xs: Csv.recordOf(header, JIterable@map(str, xs))) -
Ad-hoc factory method is provided for building
Tableinstances:# jcsv/__init__.py def __ensure_header(h): return h if isinstance(h, Header) else header(h) def __ensure_record(r, h): return r if isinstance(r, Record) else record(h, r) def table(header, *args): header = __ensure_header(header) args = [__ensure_record(row, header) for row in args] return iterable_or_varargs(args, lambda xs: Csv.tableOf(header, JIterable@xs))
Example: the jcsv package (pt. 5)
-
The
Rowclass is customised to make it more Pythonic:# jcsv/__init__.py @jpype.JImplementationFor("io.github.gciatto.csv.Row") class _Row: def __len__(self): return self.getSize() def __getitem__(self, item): if isinstance(item, int) and item < 0: item = len(self) + item try: return self.get(item) except _java.IndexOutOfBoundsException as e: raise IndexError(f"index {item} out of range") from e @property def size(self): return len(self)- supporting the syntax
len(row)instead ofrow.getSize() - supporting the syntax
row[i]instead ofrow.get(i) - supporting the syntax
row[-i]instead ofrow.get(row.getSize() - i - 1) - letting
IndexErrorbe raised instead ofIndexOutOfBoundsException - supporting the syntax
row.sizeinstead ofrow.getSize()
- supporting the syntax
Example: the jcsv package (pt. 6)
-
The
Headershall inherit all customisation forRow, plus the following ones:@jpype.JImplementationFor("io.github.gciatto.csv.Header") class _Header: @property def columns(self): return [str(c) for c in self.getColumns()] def __contains__(self, item): return self.contains(item) def index_of(self, column): return self.indexOf(column)- supporting the syntax
header.columnsinstead ofheader.getColumns() - supporting the syntax
column in headerinstead ofheader.contains(column) - supporting the syntax
header.index_of(column)instead ofheader.indexOf(column)
- supporting the syntax
Example: the jcsv package (pt. 7)
-
The
Recordshall inherit all customisation forRow, plus the following ones:@jpype.JImplementationFor("io.github.gciatto.csv.Record") class _Record: @property def header(self): return self.getHeader() @property def values(self): return [str(v) for v in self.getValues()] def __contains__(self, item): return self.contains(item)- supporting the syntax
record.headerinstead ofrecord.getHeader() - supporting the syntax
record.valuesinstead ofrecord.getValues() - supporting the syntax
value in recordinstead ofrecord.contains(value)
- supporting the syntax
Example: the jcsv package (pt. 8)
-
The
Tableclass is customised too, to make it more Pythonic:@jpype.JImplementationFor("io.github.gciatto.csv.Table") class _Table: @property def header(self): return self.getHeader() def __len__(self): return self.getSize() def __getitem__(self, item): if isinstance(item, int) and item < 0: item = len(self) + item try: return self.get(item) except _java.IndexOutOfBoundsException as e: raise IndexError(f"index {item} out of range") from e @property def records(self): return self.getRecords() @property def size(self): return len(self)- supporting the syntax
table.headerinstead oftable.getHeader() - supporting the syntax
len(table)instead oftable.getSize() - supporting the syntax
table[i]instead oftable.get(i) - supporting the syntax
table[-i]instead oftable.get(table.getSize() - i - 1) - supporting the syntax
record in tableinstead oftable.contains(record) - supporting the syntax
table.recordsinstead oftable.getRecords()
- supporting the syntax
Including .jars in JPype projects (pt. 1)
csv-python/
├── build.gradle.kts # this is where the generation of csv.jar is automated
├── jcsv
│ ├── __init__.py
│ ├── jvm
│ │ ├── __init__.py # this is where JPype is loaded
│ │ └── csv.jar # this the Fat-JAR of the JVM-based library
│ └── python.py
├── requirements.txt
└── test
├── __init__.py
├── test_parsing.py
└── test_python_api.py
-
We need to ensure that the JVM-based library is available on the system where
jcsvis installed- why not including it in the Python package?
-
The
build.gradle.ktsfile automates the generation of thecsv.jarfile- it is a Fat-JAR containing all the dependencies of the JVM-based library
- such JAR is placed in the
jcsv/jvmdirectory - it is part of Python sources, so that it can be distributed with the Python library
-
The
jcsv/jvm/__init__.pyfile loads JPype and thecsv.jarfile
Including .jars in JPype projects (pt. 2)
-
Snippet from the
build.gradle.kts:tasks.create<Copy>("createCoreJar") { group = "Python" val shadowJar by project(":csv-core").tasks.getting(Jar::class) dependsOn(shadowJar) from(shadowJar.archiveFile) { rename(".*?\\.jar", "csv.jar") } into(projectDir.resolve("jcsv/jvm")) } -
Content of the
jcsv/jvm/__init__.pyfile:import jpype from pathlib import Path # the directory where csv.jar is placed CLASSPATH = Path(__file__).parent # the list of all .jar files in CLASSPATH JARS = [str(j.resolve()) for j in CLASSPATH.glob('*.jar')] jpype.startJVM(classpath=JARS) -
Important line in
jcsv/__init__.py:import jcsv.jvmthis is forcing the startup of the JVM with the correct classpath whenever someone is using the
jcsvmodule
Including JVM in JPype projects
-
We need to ensure that some JVM is available on the system where
jcsvis installed -
Notice that the JVM is available as a Python dependency too:
-
This means that the JVM can be automatically downloaded and installed via
pip:pip install jdk4py -
… or added as a dependency to the
requirements.txtfile:JPype1==1.4.1 jdk4py==17.0.7.0 -
so, one may simply need to configure JPype to use that JVM:
# jcsv/jvm/__init__.py import jpype, sys from jdk4py import JAVA_HOME def jvm_lib_file_names(): if sys.platform == "win32": return {"jvm.dll"} elif sys.platform == "darwin": return {"libjli.dylib"} else: return {"libjvm.so"} def jvmlib(): for name in __jvm_lib_file_names(): for path in JAVA_HOME.glob(f"**/{name}"): if path.exists: return str(path) return None jpype.startJVM(jvmpath=jvmlib())
About unit testing
-
Unit tests are essential to ensure the correctness of the Pythonic API
- they prevent corruption of the Pythonic API when the JAR is updated
-
Consider for instance tests in:
test/test_parsing.pytest/test_python_api.py
-
It is important to test all the costumisations and factory methods
- because these are not covered by the unit tests of the JVM-based library