Continuous Integration
Software Process Engineering
Danilo Pianini — danilo.pianini@unibo.it
Compiled on: 2026-07-28 — printable version
Continuous Integration
The practice of integrating code with a main development line continuously
Verifying that the build remains intact
- Requires build automation to be in place
- Requires testing to be in place
- Pivot point of the DevOps practices
- Historically introduced by the extreme programming (XP) community
- Now widespread in the larger DevOps community
Traditional integration
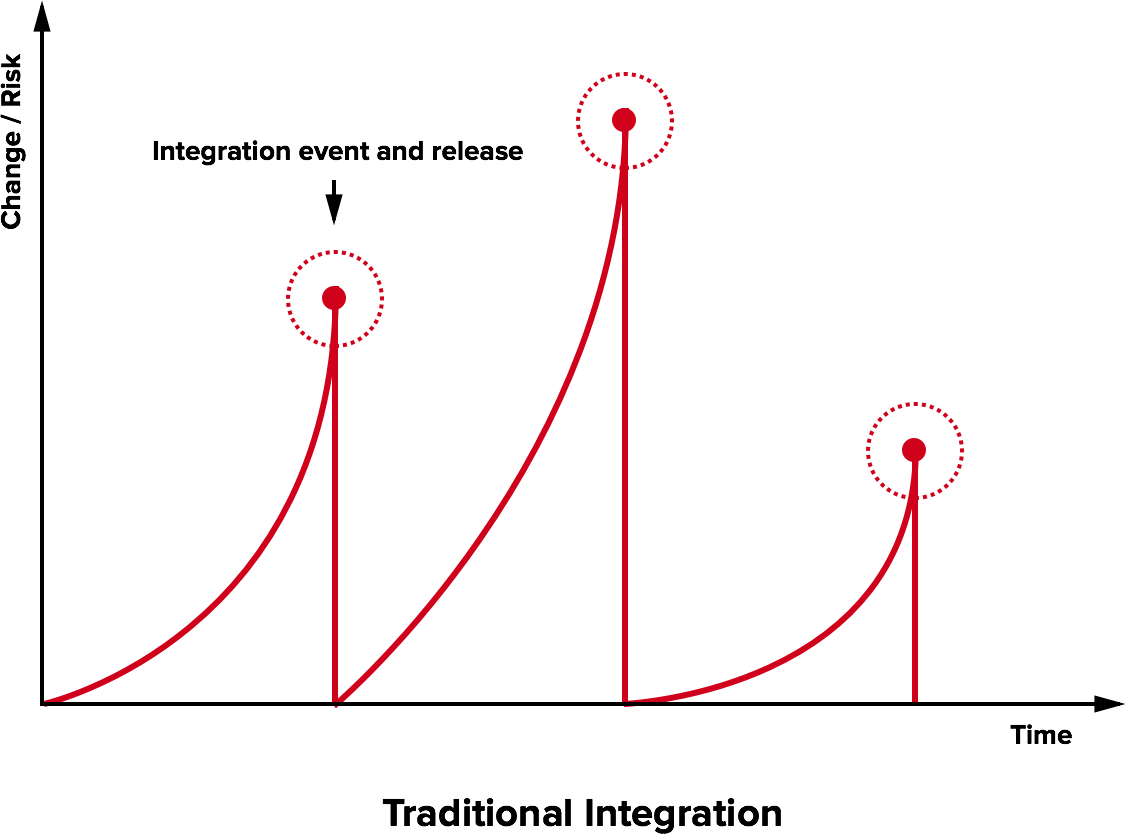
The Integration Hell
- Traditional software development takes several months for “integrating” a couple of years of development
- The longer there is no integrated project, the higher the risk
Continuous integration

Microreleases and protoduction
- High frequency integration may lead to high frequency releases
- Possibly, one per commit
- Of course, versioning must be appropriate…
Traditionally, protoduction is jargon for a prototype that ends up in production

- Traditionally used with a negative meaning
- It implied software
- unfinished,
- unpolished,
- badly designed
- Very common, unfortunately
- It implied software
- This is different in a continuously integrated environment
- Incrementality is fostered
- Partial features are up to date with the mainline
Intensive operations should be elsewhere
- The build process should be rich and fast
- Operations requiring a long time should be automated
- And run somewhere else than devs’ PCs

Continuous integration software
Software that promotes CI practices should:
- Provide clean environments for compilation/testing
- Provide a wide range of environments
- Matching the relevant specifications of the actual targets
- High degree of configurability
- Possibly, declarative configuration
- A notification system to alert about failures or issues
- Support for authentication and deployment to external services
Plenty of integrators on the market
Circle CI, Travis CI, Werker, done.io, Codefresh, Codeship, Bitbucket Pipelines, GitHub Actions, GitLab CI/CD Pipelines, JetBrains TeamCity…
Core concepts
Naming and organization is variable across platforms, but in general:
- One or more pipelines can be associated to events
- For instance, a new commit, an update to a pull request, or a timeout
- Every pipeline is composed of a sequence of operations
- Every operation could be composed of sequential or parallel sub-operations
- How many hierarchical levels are available depends on the specific platform
- GitHub Actions: workflow $\Rightarrow$ job $\Rightarrow$ step
- Travis CI: build $\Rightarrow$ stage $\Rightarrow$ job $\Rightarrow$ phase
- Execution happens in a fresh system (virtual machine or container)
- Often containers inside virtual machines
- The specific point of the hierarchy at which the VM/container is spawned depends on the CI platform
Pipeline design
In essence, designing a CI system is designing a software construction, verification, and delivery pipeline with the abstractions provided by the selected provider.
- Think of all the operations required starting from one or more blank VMs
- OS configuration
- Software installation
- Project checkout
- Compilation
- Testing
- Secrets configuration
- Delivery
- …
- Organize them in a dependency graph
- Model the graph with the provided CI tooling
Configuration can grow complex, and is usually stored in a YAML file
(but there are exceptions, JetBrains TeamCity uses a Kotlin DSL).
GitHub Actions: Structure
- Workflows react to events, launching jobs
- Multiple workflows run in parallel, unless explicitly restricted
- Jobs of the same workflow run a sequence of steps
- Multiple jobs run in parallel, unless a dependency among them is explicitly declared
- Concurrency limits can be imposed across workflows
- They can communicate via outputs
- Steps of the same job run sequentially
- They can communicate via outputs
GitHub Actions: Configuration
Workflows are configured in YAML files located in the default branch of the repository in the .github/workflows folder.
One configuration file $\Rightarrow$ one workflow
For security reasons, workflows may need to be manually activated in the Actions tab of the GitHub web interface.
GitHub Actions: Runners
Executors of GitHub actions are called runners: virtual machines (hosted by GitHub) with the GitHub Actions runner application installed.
Note: the GitHub Actions application is open source and can be installed locally, creating “self-hosted runners”. Self-hosted and GitHub-hosted runners can work together.
Upon their creation, runners have a default environment, which depends on their operating system
Convention over configuration
Several CI systems inherit the “convention over configuration” principle.
For instance, by default (with an empty configuration file) Travis CI builds a Ruby project using rake.
GitHub actions does not adhere to the principle: if left unconfigured, the runner does nothing (it does not even clone the repository locally).
Probable reason: Actions is an all-round repository automation system for GitHub, not just a “plain” CI/CD pipeline
$\Rightarrow$ It can react to many different events, not just changes to the git repository history
GHA: basic workflow structure
Minimal, simplified workflow structure:
# Mandatory workflow name
name: Workflow Name
on: # Events that trigger the workflow
jobs: # Jobs composing the workflow, each one will run on a different runner
Job-Name: # Every job must be named
# The type of runner executing the job, usually the OS
runs-on: runner-name
steps: # A list of commands, or "actions"
- # first step
- # second step
Another-Job: # This one runs in parallel with Job-Name
runs-on: '...'
steps: [ ... ]
DRY with YAML
We discussed that automation / integration pipelines are part of the software
- They are subject to the same (or even higher) quality standards
- All the good engineering principles apply!
YAML is often used by CI integrators as preferred configuration language as it enables some form of DRY:
- Anchors (
&/*) - Merge keys (
<<:)
hey: &ref
look: at
me: [ "I'm", 'dancing' ]
merged:
foo: *ref
<<: *ref
look: to
Same as:
hey: { look: at, me: [ "I'm", 'dancing' ] }
merged: { foo: { look: at, me: [ "I'm", 'dancing' ] }, look: to, me: [ "I'm", 'dancing' ] }
GitHub Actions’ actions
GHA’s YAML parser recently (and after a long time) added support for YAML anchors but does not support merge keys.
- there is a workaround but it is very custom
GHA achieves reuse via:
- “actions”: reusable parameterizable steps
- JavaScript (working on any OS)
- Docker container-based (linux only)
- Composite (assemblage of other actions)
- “reusable workflows”: reusable and parameterizable jobs
Many actions are provided by GitHub directly, and many are developed by the community.
Workflow minimal example
# This is a basic workflow to help you get started with Actions
name: Example workflow
# Controls when the workflow will run
on:
push:
tags: '*'
branches-ignore: # Pushes on these branches won't start a build
- 'autodelivery**'
- 'bump-**'
- 'renovate/**'
paths-ignore: # Pushes that change only these file won't start the workflow
- 'README.md'
- 'CHANGELOG.md'
- 'LICENSE'
pull_request:
branches: # Only pull requests based on these branches will start the workflow
- master
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:Workflow minimal example
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
Default-Example:
# The type of runner that the job will run on
runs-on: macos-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@0c366fd6a839edf440554fa01a7085ccba70ac98
# Runs a single command using the runners shell
- name: Run a one-line script
run: echo Hello from a ${{ runner.os }} machine!
# Runs a set of commands using the runners shell
- name: Run a multi-line script
run: |
echo Add other actions to build,
echo test, and deploy your project.Workflow minimal example
Explore-GitHub-Actions:
runs-on: ubuntu-latest
steps:
- run: echo "🎉 The job was automatically triggered by a ${{ github.event_name }} event."
- run: echo "🐧 This job is now running on a ${{ runner.os }} server hosted by GitHub!"
- run: echo "🔎 The name of your branch is ${{ github.ref }} and your repository is ${{ github.repository }}."
- name: Check out repository code
uses: actions/checkout@v7
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- run: echo "🖥️ The workflow is now ready to test your code on the runner."
- name: List files in the repository
run: ls ${{ github.workspace }}
- run: echo "🍏 This job's status is ${{ job.status }}."
# Steps can be executed conditionally
- name: Skipped conditional step
if: runner.os == 'Windows'
run: echo this step won't run, it has been excluded!
- run: |
echo This is
echo a multi-line
echo script.Workflow minimal example
Conclusion:
runs-on: windows-latest
# Jobs may require other jobs
needs: [ Default-Example, Explore-GitHub-Actions ]
# Typically, steps that follow failed steps won't execute.
# However, this behavior can be changed by using the built-in function "always()"
if: always()
steps:
- name: Run something on powershell
run: echo By default, ${{ runner.os }} runners execute with powershell
- name: Run something on bash
shell: bash
run: echo However, it is allowed to force the shell type and there is a bash available for ${{ runner.os }} too.
GHA expressions
GitHub Actions allows expressions to be included in the workflow file
- Syntax:
${{ <expression> }} - Special rule:
if:conditionals are automatically evaluated as expressions, so${{ }}is unnecessaryif: <expression>works just fine
The language is rather limited, and documented at
-
https://docs.github.com/en/actions/learn-github-actions/expressions
-
The language performs a loose equality
- Equal types are compared
- Different types are coerced to integers when compared
-
When a string is required, any type is coerced to string
- String comparison ignores case
GHA Expressions Types
| Type | Literal | Number coercion | String coercion |
|---|---|---|---|
| Null | null |
0 |
'' |
| Boolean | true or false |
true: 1, false: 0 |
'true' or 'false' |
| String | '...' (mandatorily single quoted) |
Javascript’s parseInt, with the exception that '' is 0 |
none |
| JSON Array | unavailable | NaN |
error |
| JSON Object | unavailable | NaN |
error |
Arrays and objects exist and can be manipulated, but cannot be created
GHA Expressions Operators
- Grouping with
( ) - Array access by index with
[ ] - Object deference with
. - Logic operators: not
!, and&&, or|| - Comparison operators:
==,!=,<,<=,>,>=
GHA Expressions Functions
Functions cannot be defined. Some are built-in, their expressivity is limited. They are documented at
https://docs.github.com/en/actions/learn-github-actions/expressions#functions
Job status check functions
success():trueif none of the previous steps failed- By default, every step has an implicit
if: success()conditional
- By default, every step has an implicit
always(): alwaystrue, causes the step evaluation even if previous failed, but supports combinationsalways() && <expression returning false>evaluates the expression and does not run the step
cancelled():trueif the workflow execution has been canceledfailure():trueif a previous step of any previous job has failed
The GHA context
The expression can refer to some objects provided by the context. They are documented at
https://docs.github.com/en/actions/learn-github-actions/contexts
Some of the most useful are the following
github: information on the workflow context.event_name: the event that triggered the workflow.repository: repository name.ref: branch or tag that triggered the workflow- e.g.,
refs/heads/<branch>refs/tags/<tag>
- e.g.,
env: access to the environment variablessteps: access to previous step information.<step id>.outputs.<output name>: information exchange between steps
runner:.os: the operating system
secrets: access to secret variables (in a moment…)matrix: access to the build matrix variables (in a moment…)
Checking out the repository
By default, GitHub actions’ runners do not check out the repository
- Actions may not need to access the code
- e.g., Actions automating issues, projects
It is a common and non-trivial operation (the checked out version must be the version originating the workflow), thus GitHub provides an action:
- name: Check out repository code
uses: actions/checkout@v7Since actions typically do not need the entire history of the project, by default the action checks out only the commit that originated the workflow (--depth=1 when cloning)
- Shallow cloning has better performance
- $\Rightarrow$ It may break operations that rely on the entire history!
- e.g., the git-sensitive semantic versioning system
Also, tags don’t get checked out
Checking out the whole history
- name: Checkout with default token
uses: actions/checkout@v7.0.1
if: inputs.token == ''
with:
fetch-depth: 0
submodules: recursive
- name: Fetch tags
shell: bash
run: git fetch --tags -f
(code from a custom action, ignore the if)
- Check out the repo with the maximum depth
- Recursively check out all submodules
- Checkout all tags
Writing outputs
Communication with the runner happens via workflow commands
The simplest way to send commands is to print on standard output a message in the form:
::workflow-command parameter1={data},parameter2={data}::{command value}
In particular, actions can set outputs by printing:
::set-output name={name}::{value}
echo "{name}={value}" >> "$GITHUB_OUTPUT"
jobs:
Build:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: danysk/action-checkout@0.2.31
- id: branch-name # Custom id
uses: tj-actions/branch-names@v9
- id: output-from-shell
run: ruby -e 'puts "dice=#{rand(1..6)}"' >> $GITHUB_OUTPUT
- run: |
echo "The dice roll resulted in number ${{ steps.output-from-shell.outputs.dice }}"
if ${{ steps.branch-name.outputs.is_tag }} ; then
echo "This is tag ${{ steps.branch-name.outputs.tag }}"
else
echo "This is branch ${{ steps.branch-name.outputs.current_branch }}"
echo "Is this branch the default one? ${{ steps.branch-name.outputs.is_default }}"
fi
Build matrix
Most software products are meant to be portable
- Across operating systems
- Across different frameworks and languages
- Across runtime configuration
A good continuous integration pipeline should test all the supported combinations
- or a sample, if the performance is otherwise unbearable
The solution is the adoption of a build matrix
- Build variables and their allowed values are specified
- The CI integrator generates the cartesian product of the variable values, and launches a build for each!
- Note: there is no built-in feature to exclude some combination
- It must be done manually using
ifconditionals
- It must be done manually using
Build matrix in GHA
jobs:
Build:
strategy:
matrix:
os: [windows, macos, ubuntu]
jvm_version: [8, 11, 15, 16] # Arbitrarily-made and arbitrarily-valued variables
ruby_version: [2.7, 3.0]
python_version: [3.7, 3.9.12]
runs-on: ${{ matrix.os }}-latest ## The string is computed interpolating a variable value
steps:
- uses: actions/setup-java@v5
with:
distribution: 'adopt'
java-version: ${{ matrix.jvm_version }} # "${{ }}" contents are interpreted by the github actions runner
- uses: actions/setup-python@v7
with:
python-version: ${{ matrix.python_version }}
- uses: ruby/setup-ruby@v1
with:
ruby-version: ${{ matrix.ruby_version }}
- shell: bash
run: java -version
- shell: bash
run: ruby --version
- shell: bash
run: python --version
Private data and continuous integration
We would like the CI to be able to
- Sign our artifacts
- Delivery/Deploy our artifacts on remote targets
Both operations require private information to be shared
Of course, private data can’t be shared
- Attackers may steal the identity
- Attackers may compromise deployments
- In case of open projects, attackers may exploit pull requests!
- Fork your project (which has e.g. a secret environment variable)
- Print the value of the secret (e.g. with
printenv)
How to share a secret with the build environment?
Secrets
Secrets can be stored in GitHub at the repository or organization level.
GitHub Actions can access these secrets from the context:
- Using the
secrets.<secret name>context object - Access is allowed only for workflows generated by local events
- Namely, no secrets for pull requests
Secrets can be added from the web interface (for mice lovers), or via the GitHub API.
#!/usr/bin/env ruby
require 'rubygems'
require 'bundler/setup'
require 'octokit'
require 'rbnacl'
repo_slug, name, value = ARGV
client = Octokit::Client.new(:access_token => 'access_token_from_github')
pubkey = client.get_public_key(repo_slug)
key = Base64.decode64(pubkey.key)
sodium_box = RbNaCl::Boxes::Sealed.from_public_key(key)
encrypted_value = Base64.strict_encode64(sodium_box.encrypt(value))
payload = { 'key_id' => pubkey.key_id, 'encrypted_value' => encrypted_value }
client.create_or_update_secret(repo_slug, name, payload)
In-memory signatures
Signing in CI is easier if the key can be stored in memory
the alternative is to install a private key in the runner
To do so we need to:
- Find a way to write our key in memory
- Export it safely into the CI environment (via a secret)
- Configure the build system to use the key in-memory when a CI environment is detected
Step 1: exporting GPG private keys
gpg --armor --export-secret-key <key id>
Exports a base64-encoded version of your binary key, with a header and a footer.
-----BEGIN PGP PRIVATE KEY BLOCK-----
M4ATvaZBpT5QjAvOUm09rKsvouXYQE1AFlmMfJQTUlmOA_R6b-SolgYFOx_cKAAL
Vz1BIv8nvzg9vFkAFhB7N7QGwYfzbKVAKhS0IDQutDISutMTS3ujJlvKuQRdoE2z
...
WjEW1UmgYOXLawcaXE2xaDxoXz1FLVxxqZx-LZg_Y/0tsB==
=IN7o
-----END PGP PRIVATE KEY BLOCK-----
Note: armoring is not encryption
- it is meant for readability and processing with text-based tools
Step 2: export the key as a CI secret
-
In most CI systems, secrets allow enough space for an armored GPG private keys to fit in
- It is the case for GHA
-
In this case, just export the armored version as a secret
-
Otherwise:
- Encrypt your secret with a (much shorter) symmetric key into a file
- Store the key as a secret (it will fit as it is much smaller than an asymmetric key)
- Track the encrypted file in your repo
- Before signing (and only if needed), unencrypt the file and load it in-memory
- then delete the unencrypted version
- you want to reduce the probability that the file gets delivered…
Step 3: tell the build system to use in-memory keys when in CI
How to tell if you are in CI or not?
- The
CIenvironment variable is automatically set to"true"on most CI environments- Including GitHub Actions
In Gradle
if (System.getenv("CI") == true.toString()) {
signing {
val signingKey: String? by project
val signingPassword: String? by project
useInMemoryPgpKeys(signingKey, signingPassword)
}
}
- The
signingKeyandsigningPasswordproperties must get passed to Gradle- One way is to pass them on the command line:
./gradlew -PsignigngKey=... -PsigningPassword=... <tasks>
- Alternatively, they can be stored into environment variables
- Gradle auto-imports properties named
ORG_GRADLE_PROJECT_<variableName> - So, in GitHub actions:
- Gradle auto-imports properties named
- One way is to pass them on the command line:
env:
ORG_GRADLE_PROJECT_signingKey: ${{ secrets.SIGNING_KEY }}
ORG_GRADLE_PROJECT_signingPassword: ${{ secrets.SIGNING_PASSWORD }}
DRY with GitHub Actions
Imperative behaviour in GitHub Actions is encapsulated into actions
Actions are executed as a single logical step, with inputs and outputs
Their metadata is written in a actions.yml file on the repository root
GitHub actions stored on GitHub are usable without further deployment steps
- By using
owner/repo@<tree-ish>as reference
GitHub Actions’ metadata
name: 'A string with the action name'
description: 'A long description explaining what the action does'
inputs:
input-name: # id of input
description: 'Input description'
required: true # whether it should be mandatorily specified
default: 'default value' # Default value, if not specified by the caller
outputs:
# Outputs will be set by the action when running
output-name: # id of output
description: 'Description of the output'
runs: # Content depends on the action type
Composite actions: structure
Composite actions allow the execution of multiple steps that can be scripts or other actions.
runs:
using: composite
steps: [ <list of steps> ]
Composite actions: example
The action is contained in its metadata descriptor action.ymlroot, e.g.:
name: 'Checkout the whole repository'
description: 'Checkout all commits, all tags, and initialize all submodules.'
inputs:
token:
description: The token to use when checking out the repository
required: false
default: ''
runs:
using: "composite"
steps:
- name: Checkout with custom token
uses: actions/checkout@v7.0.1
if: inputs.token != ''
with:
fetch-depth: 0
submodules: recursive
token: ${{ inputs.token }}
- name: Checkout with default token
uses: actions/checkout@v7.0.1
if: inputs.token == ''
with:
fetch-depth: 0
submodules: recursive
- name: Fetch tags
shell: bash
run: git fetch --tags -f
Composite actions: usage
It can be used with:
steps:
# Checkout the repository
- name: Checkout
uses: danysk/checkout-classic@1.0.0Composite actions: limitations
- No support for secrets, they must be passed as inputs
For instance this way:
name: 'Composite action with a secret'
description: 'For teaching purposes'
inputs:
token: # github token
description: 'Github token for deployment. Skips deployment otherwise.'
required: true
runs:
using: "composite"
steps:
- run: '[[ -n "${{ inputs.token }}" ]] || false'
name: Fail if the token is unset
No conditional steps (ouch…)They can be somewhat emulated inside the script
- Conditional steps introduced November 9th 2021
Docker container actions
Wait, what is a container?
- We might need to deviate for a moment: » click here! «
How to
- Configure the
Dockerfileof the container you want to use - Prepare the main script and declare it as
ENTRYPOINT - Define inputs and outputs in
action.yml - In the
runssection setusing: dockerand the arguments order- The order is relevant, they will be passed to the entrypoint script in order
runs:
using: 'docker'
image: 'Dockerfile' # Alternatively, the name of an existing image
args:
- ${{ inputs.some-input-name }}
- Docker container actions work only on Linux
JavaScript actions
The most flexible way of writing actions
- Portable across OSs
runs:
using: 'node12'
main: 'index.js'
- Initialize a new NPM project:
npm init -y - Install the toolkits you will use:
npm install @actions/<toolkitname> - write your code
const core = require('@actions/core');
try {
const foo = core.getInput('some-input');
console.log(`Hello ${foo}!`);
} catch (error) {
core.setFailed(error.message);
}
Reusable workflows
GitHub actions also allows to configure reusable workflows
- Similar in concept to composite actions, but capture larger operations
- They can preconfigure matrices
- Conditional steps are supported
- Limitation: can’t be used in
workflow_dispatchif they have more than 10 parameters - Limitation: can’t be used recursively
- Limitation: changes to the environment variables (
envcontext object) of the caller are not propagated to the callee - Limitation: the callee has no implicit access to the caller’s secrets
- But they can be passed down
Still, the mechanism enables to some extent the creation of libraries of reusable workflows
Defining Reusable workflows
name: ...
on:
workflow_call: # Trigger when someone calls the workflow
inputs:
input-name:
description: optional description
default: optional default (otherwise, it is assigned to a previous)
required: true # Or false, mandatory
type: string # Mandatory: string, boolean, or number
secrets: # Secrets are listed separately
token:
required: true
jobs:
Job-1:
... # It can use a matrix, different OSs, and
Job-2:
... # Multiple jobs are okay!
Reusing a workflow
Similar to using an action!
usesis applied to the entire job- further
stepscannot be defined
name: ...
on:
push:
pull_request:
#any other event
jobs:
Build:
uses: owner/repository/.github/workflows/build-and-deploy-gradle-project.yml@<tree-ish>
with: # Pass values for the expected inputs
deploy-command: ./deploy.sh
secrets: # Pass down the secrets if needed
github-token: ${{ secrets.GITHUB_TOKEN }}
$\Rightarrow$ write workflows, use jobs
Stale builds
- Stuff works
- Nobody touches it for months
- Untouched stuff is now borked!
Ever happened?
- Connected to the issue of build reproducibility
- The higher the build reproducibility, the higher its robustness
- The default runner configuration may change
- Some tools may become unavailable
- Some dependencies may get unavailable
The sooner the issue is known, the better
$\Rightarrow$ Automatically run the build every some time even if nobody touches the project
- How often? Depends on the project…
- Warning: GitHub Actions disables
cronCI jobs if there is no action on the repository, which makes the mechanism less useful
GitHub CLI
GitHub CLI: What and Why
-
ghis the official CLI for GitHub -
Targets GitHub features that
gitdoes not cover- issues, pull requests, releases, workflows, notifications, secrets, API
-
Works in terminals and scripts
-
Auth once, reuse across repos and orgs
Setup and Auth
Install from package manager, then:
gh --version
gh auth login # guided OAuth or token
gh auth status # verify
gh config set prompt disabled true # non-interactive scripts
gh alias set prd 'pr create -d -f' # example alias
Multiple accounts:
gh auth login --hostname github.com --scopes repo,workflow
gh auth switch --user <handle>
Daily Ops: Issues and PRs
Issues:
gh issue list --label bug --state open
gh issue create -t "Crash on startup" -b "Steps…" -l bug -a @me
gh issue view 123 -w # open in browser
Pull requests:
gh pr create -t "Fix: null check" -b "…" -B main -H feat/guard -r org/team
gh pr checks # status of CI
gh pr review --approve
gh pr merge --auto --squash
Releases and notifications:
gh release create v1.2.0 dist/* -t "v1.2.0" -n "Changelog…"
gh notif list --unread
CI/CD, Secrets, and Raw API
Workflows:
gh workflow list
gh run list
gh run watch --job 123456789
gh workflow run build.yml -f ref=main
Secrets:
gh secret set NPM_TOKEN --body "$NPM_TOKEN" # repo
gh secret set PROD_KEY --org <org> --repos 'app-*' # org with repo filter
REST access when features lag:
gh api repos/{owner}/{repo}/actions/runs --paginate | jq '.workflow_runs[].status'
gh api graphql -f query='query { viewer { login } }'
Tip: compose gh with jq, xargs, and bash for reliable automation.
Additional checks and reporting
There exist a number of recommended services that provide additional QA and reports.
Non exhaustive list:
- Codecov.io
- Code coverage
- Supports Jacoco XML reports
- Nice data reporting system
- Sonarcloud
- Multiple measures, covering reliability, security, maintainability, duplication, complexity…
- Codacy
- Automated software QA for several languages
- Code Factor
- Automated software QA
High quality FLOSS checklist
The Linux Foundation Core Infrastructure Initiative created a checklist for high quality FLOSS.
CII Best Practices Badge Program https://bestpractices.coreinfrastructure.org/en
- Self-certification: no need for bureaucracy
- Provides a nice TODO list for a high quality product
- Releases a badge that can be added e.g. to the project homepage
Advanced workflow automation
Automated evolution
A full-fledged CI system allows reasonably safe automated evolution of software
At least, in terms of dependency updates
Assuming that you can effectively intercept issues, here is a possible workflow for automatic dependency updates:
- Check if there are new updates
- Apply the update in a new branch
- Open a pull request
- Verify if changes break anything
- If they do, manual intervention is required
- Merge (or rebase, or squash)
Automated evolution
Bots performing the aforementioned process for a variety of build systems exist.
They are usually integrated with the repository hosting provider
- Whitesource Renovate (Multiple)
- Also updates github actions and Gradle Catalogs
- Dependabot (Multiple)
- Gemnasium (Ruby)
- Greenkeeper (NPM)
Copilot coding agent: what it is
- Cloud-hosted autonomous LLM agent inside GitHub.
- Can be assigned issues
- Spins up an isolated runner, clones the repo, makes changes, builds, and proceeds iteratively until the issue is solved.
- (or Copilot “thinks” it is solved)
- Responds with a draft PR for review.
- Operates through GitHub Actions with full audit trail in commits and logs (consuming actions minutes).
How to use it
- Start from: assign an Issue to Copilot.
- It opens a draft PR, and requests your review.
- At the first assignment on a new repo, it will ask for an onboarding procedure
- When onboarding, Copilot runs through the repository and prepares a document
in
.github/copilot-instructions.mdfor his future self with a summary of the codebase. - On subsequent runs, this summary is used as context for Copilot, speeding up its understanding of the codebase.
- When onboarding, Copilot runs through the repository and prepares a document
in
- At the first assignment on a new repo, it will ask for an onboarding procedure
- Tag
@Copilotin PR comments to guide it.
Impact
The literature is emerging, initial results are mixed.
- GenAI seems to speed up unexperieced developers in small and simple projects.
- Experienced developers on large projects seem to be slowed down (-19%) by the need to review AI-generated code.
Issue and PR templating
Helping humans helping you helping them
Some tasks do require humans:
- Reporting bugs
- Explaining the contents of a human-made pull request
However, we may still want these documents to follow a template
- Remind contributors to enter all the information needed to tackle the issue correctly
- for instance, instructions on how to reproduce a bug
- Pre-fill common information
- Enforce or propose a structure
- For instance, semantic PR titles
Most Git hosting services allow to specify a template.
Repo templates in GitHub
Templates in GitHub are special files found in the .github folder,
written in YAML or Markdown, and stored on the default branch.
The descriptor generates a form that users must fill.
They are available for both issues and pull requests, and share most of the syntax.
Location of templates in GitHub
.github
├── PULL_REQUEST_TEMPLATE
│ ├── config.yml
│ ├── example.yml
│ └── another-example.md
└── ISSUE_TEMPLATE
├── config.yml
├── example.yml
└── another-example.md
Any md or yml file located in .github/ISSUE_TEMPLATE
is considered as a template for issues
Any md or yml file located in .github/PULL_REQUEST_TEMPLATE
is considered as a template for pull requests
If a single template is necessary,
a single .github/ISSUE_TEMPLATE.md or .github/PULL_REQUEST_TEMPLATE.md file
replaces the content of the whole directory
Forms and templates in GitHub
- Plain markdown documents are used to pre-populate the content of the PR message (templates)
- A YAML front-matter can be used to specify options
---
name: 🐞 Bug
about: File a bug/issue
title: '[BUG] <title>'
labels: bug, to-triage
assignees: someone, someoneelse
---
### Current Behavior:
<!-- A concise description of what you're experiencing. -->
### Expected Behavior:
<!-- A concise description of what you expected to happen. -->
### Steps to reproduce:
1. first do...
2. and then...
- YAML documents are used to build richer documents as forms
- YAML documents can be used to build the same forms as markdown ones, with a pre-populated text area
- They can also be used to build forms with checkboxes and some forms of validation
- Reference syntax: https://bit.ly/3yvrXqE
Continuous Integration
Software Process Engineering
Danilo Pianini — danilo.pianini@unibo.it
Compiled on: 2026-07-28 — printable version